Okazaki fragments → DNA replication — Okazaki fragments
olfactory receptorOlfactory receptors (ORs), also known as odorant receptors, are expressed in the cell membranes of olfactory receptor neurons and are responsible for the detection of odorants (i.e., compounds that have an odor) which give rise to the sense of smell. Activated olfactory receptors trigger nerve impulses which transmit information about odor to the brain. These receptors are members of the class A rhodopsin-like family of G protein-coupled receptors (GPCRs). The olfactory receptors form a multigene family consisting of around 800 genes in humans and 1400 genes in mice. (W)
Oligonucleotide synthesis is the chemical synthesis of relatively short fragments of nucleic acids with defined chemical structure (sequence). The technique is extremely useful in current laboratory practice because it provides a rapid and inexpensive access to custom-made oligonucleotides of the desired sequence. Whereas enzymes synthesize DNA and RNA only in a 5' to 3' direction, chemical oligonucleotide synthesis does not have this limitation, although it is most often carried out in the opposite, 3' to 5' direction. Currently, the process is implemented as solid-phase synthesis using phosphoramidite method and phosphoramidite building blocks derived from protected 2'-deoxynucleosides (dA,dC,dG, and T),ribonucleosides (A,C,G, and U), or chemically modified nucleosides, e.g. LNA or BNA.
To obtain the desired oligonucleotide, the building blocks are sequentially coupled to the growing oligonucleotide chain in the order required by the sequence of the product (see Synthetic cycle below). The process has been fully automated since the late 1970s. Upon the completion of the chain assembly, the product is released from the solid phase to solution, deprotected, and collected. The occurrence of side reactions sets practical limits for the length of synthetic oligonucleotides (up to about 200 nucleotide residues) because the number of errors accumulates with the length of the oligonucleotide being synthesized. Products are often isolated by high-performance liquid chromatography (HPLC) to obtain the desired oligonucleotides in high purity. Typically, synthetic oligonucleotides are single-stranded DNA or RNA molecules around 15–25 bases in length.
open reading frame
In molecular genetics, an open reading frame (ORF) is the part of a reading frame that has the ability to be translated. An ORF is a continuous stretch of codons that begins with a start codon (usually AUG) and ends at a stop codon (usually UAA, UAG or UGA). An ATG codon (AUG in terms of RNA) within the ORF (not necessarily the first) may indicate where translation starts. The transcription termination site is located after the ORF, beyond the translationstop codon. If transcription were to cease before the stop codon, an incomplete protein would be made during translation. In eukaryoticgenes with multiple exons,introns are removed and exons are then joined together after transcription to yield the final mRNA for protein translation. In the context of gene finding, the start-stop definition of an ORF therefore only applies to spliced mRNAs, not genomic DNA, since introns may contain stop codons and/or cause shifts between reading frames. An alternative definition says that an ORF is a sequence that has a length divisible by three and is bounded by stop codons. This more general definition can also be useful in the context of transcriptomics and/or metagenomics, where start and/or stop codon may not be present in the obtained sequences. Such an ORF corresponds to parts of a gene rather than the complete gene.(W)
Example of a six-frame translation. The nucleotide sequence is shown in the middle with forward translations above and reverse translations below. Two possible open reading frames with the sequences are highlighted.
operon
In genetics, an operon is a functioning unit of DNA containing a cluster of genes under the control of a single promoter. The genes are transcribed together into an mRNA strand and either translated together in the cytoplasm, or undergo splicing to create monocistronic mRNAs that are translated separately, i.e. several strands of mRNA that each encode a single gene product. The result of this is that the genes contained in the operon are either expressed together or not at all. Several genes must be co-transcribed to define an operon.
Originally, operons were thought to exist solely in prokaryotes (which includes organelles like plastids that are derived from bacteria), but since the discovery of the first operons in eukaryotes in the early 1990s, more evidence has arisen to suggest they are more common than previously assumed. In general, expression of prokaryotic operons leads to the generation of polycistronic mRNAs, while eukaryotic operons lead to monocistronic mRNAs.
Operons are also found in viruses such as bacteriophages. For example, T7 phages have two operons. The first operon codes for various products, including a special T7 RNA polymerase which can bind to and transcribe the second operon. The second operon includes a lysis gene meant to cause the host cell to burst. (W)
An organic acid is an organic compound with acidic properties. The most common organic acids are the carboxylic acids, whose acidity is associated with their carboxyl group –COOH. Sulfonic acids, containing the group –SO2OH, are relatively stronger acids. Alcohols, with –OH, can act as acids but they are usually very weak. The relative stability of the conjugate base of the acid determines its acidity. Other groups can also confer acidity, usually weakly: the thiol group –SH, the enol group, and the phenol group. In biological systems, organic compounds containing these groups are generally referred to as organic acids.
An organic base is an organic compound which acts as a base. Organic bases are usually, but not always, proton acceptors. They usually contain nitrogen atoms, which can easily be protonated, for example amines have a lone pair of electrons on the nitrogen atom and can thus act as proton acceptors (bases).. Organic bases combine with monosaccharides to form nucleotides. Amines and nitrogen-containing heterocyclic compounds are organic bases. Examples include:
Three representations of an organic compound, 5α-Dihydroprogesterone (5α-DHP), a steroid hormone. For molecules showing color, the carbon atoms are in black, hydrogens in gray, and oxygens in red. In the line angle representation, carbon atoms are implied at every terminus of a line and vertex of multiple lines, and hydrogen atoms are implied to fill the remaining needed valences (up to 4).
organic compound (organic molecule)
In chemistry,organic compounds are generally any chemical compounds that contain carbon-hydrogenbonds. Due to carbon's ability to catenate (form chains with other carbon atoms), millions of organic compounds are known. The study of the properties, reactions, and syntheses of organic compounds comprises the discipline known as organic chemistry. For historical reasons, a few classes of carbon-containing compounds (e.g., carbonate anion salts and cyanide salts), along with a handful of other exceptions (e.g., carbon dioxide), are not classified as organic compounds and are considered inorganic. Other than those just named, little consensus exists among chemists on precisely which carbon-containing compounds are excluded, making any rigorous definition of an organic compound elusive. (W)
The L-isoleucine molecule, C6H13NO2, showing features typical of organic compounds. Carbon atoms are in black, hydrogens gray, oxygens red, and nitrogen blue.
organic matterOrganic matter, organic material, or natural organic matter refers to the large source of carbon-based compounds found within natural and engineered, terrestrial and aquatic environments. It is matter composed of organic compounds that have come from the remains of organisms such as plants and animals and their waste products in the environment. Organic molecules can also be made by chemical reactions that don't involve life. Basic structures are created from cellulose,tannin,cutin, and lignin, along with other various proteins,lipids, and carbohydrates. Organic matter is very important in the movement of nutrients in the environment and plays a role in water retention on the surface of the planet.(W)
origin of replication
The origin of replication (also called the replication origin) is a particular sequence in a genome at which replication is initiated. Propagation of the genetic material between generations requires timely and accurate duplication of DNA by semiconservative replication prior to cell division to ensure each daughter cell receives the full complement of chromosomes. This can either involve the replication of DNA in living organisms such as prokaryotes and eukaryotes, or that of DNA or RNA in viruses, such as double-stranded RNA viruses. Synthesis of daughter strands starts at discrete sites, termed replication origins, and proceeds in a bidirectional manner until all genomic DNA is replicated. Despite the fundamental nature of these events, organisms have evolved surprisingly divergent strategies that control replication onset. Although the specific replication origin organization structure and recognition varies from species to species, some common characteristics are shared.(W)
Models for bacterial (A) and eukaryotic (B) DNA replication initiation. A) Circular bacterial chromosomes contain a cis-acting element, the replicator, that is located at or near replication origins. i) The replicator recruits initiator proteins in a DNA sequence-specific manner, which results in melting of the DNA helix and loading of the replicative helicase onto each of the single DNA strands (ii). iii) Assembled replisomes bidirectionally replicate DNA to yield two copies of the bacterial chromosome. B) Linear eukaryotic chromosomes contain many replication origins. Initiator binding (i) facilitates replicative helicase loading (ii) onto duplex DNA to license origins. iii) A subset of loaded helicases is activated for replisome assembly. Replication proceeds bidirectionally from origins and terminates when replication forks from adjacent active origins meet (iv)..
Origin organization and recognition in bacteria. A) Schematic of the architecture of E. coli origin oriC, Thermotoga maritima oriC, and the bipartite origin in Helicobacter pylori. The DUE is flanked on one side by several high- and weak-affinity DnaA-boxes as indicated for E. coli oriC.
B) Domain organization of the E. coli initiator DnaA. Magenta circle indicates the single-strand DNA binding site.
C) Models for origin recognition and melting by DnaA. In the two-state model (left panel), the DnaA protomers transition from a dsDNA binding mode (mediated by the HTH-domains recognizing DnaA-boxes) to an ssDNA binding mode (mediated by the AAA+ domains). In the loop-back model, the DNA is sharply bent backwards onto the DnaA filament (facilitated by the regulatory protein IHF) so that a single protomer binds both duplex and single-stranded regions. In either instance, the DnaA filament melts the DNA duplex and stabilizes the initiation bubble prior to loading of the replicative helicase (DnaB in E. coli). HTH – helix-turn-helix domain, DUE – DNA unwinding element, IHF – integration host factor.
Origin organization and recognition in archaea. A) The circular chromosome of Sulfolobus solfataricus contains three different origins.
B) Arrangement of initiator binding sites at two S. solfataricus origins, oriC1 and oriC2. Orc1-1 association with ORB elements is shown for oriC1. Recognition elements for additional Orc1/Cdc6 paralogs are also indicated, while WhiP binding sites have been omitted.
C) Domain architecture of archaeal Orc1/Cdc6 paralogs. The orientation of ORB elements at origins leads to directional binding of Orc1/Cdc6 and MCM loading in between opposing ORBs (in B). (m)ORB – (mini-)origin recognition box, DUE – DNA unwinding element, WH – winged-helix domain.
Origin organization and recognition in eukaryotes. Specific DNA elements and epigenetic features involved in ORC recruitment and origin function are summarized for S. cerevisiae, S. pombe, and metazoan origins. A schematic of the ORC architecture is also shown, highlighting the arrangement of the AAA+ and winged-helix domains into a pentameric ring that encircles origin DNA. Ancillary domains of several ORC subunits involved in targeting ORC to origins are included. Other regions in ORC subunits may also be involved in initiator recruitment, either by directly or indirectly associating with partner proteins. A few examples are listed. Note that the BAH domain in S. cerevisiae Orc1 binds nucleosomes but does not recognize H4K20me2. BAH – bromo-adjacent homology domain, WH – winged-helix domain, TFIIB – transcription factor II B-like domain in Orc6, G4 – G quadruplex, OGRE – origin G-rich repeated element.
ORC directs DNA replication throughout the genome and is required for its initiation. ORC bound at replication origins serves as the foundation for assembly of the pre-replication complex (pre-RC), which includes Cdc6, Tah11 (a.k.a. Cdt1), and the Mcm2-Mcm7 complex. Pre-RC assembly during G1 is required for replication licensing of chromosomes prior to DNA synthesis during S phase. Cell cycle-regulated phosphorylation of Orc2, Orc6, Cdc6, and MCM by the cyclin-dependent protein kinaseCdc28 regulates initiation of DNA replication, including blocking reinitiation in G2/M phase.
The ORC is present throughout the cell cycle bound to replication origins, but is only active in late mitosis and early G1.
In yeast, ORC also plays a role in the establishment of silencing at the mating-typeloci Hidden MAT Left (HML) and Hidden MAT Right (HMR). ORC participates in the assembly of transcriptionally silent chromatin at HML and HMR by recruiting the Sir1 silencing protein to the HML and HMR silencers.
Both Orc1 and Orc5 bind ATP, though only Orc1 has ATPase activity. The binding of ATP by Orc1 is required for ORC binding to DNA and is essential for cell viability. The ATPase activity of Orc1 is involved in formation of the pre-RC. ATP binding by Orc5 is crucial for the stability of ORC as a whole. Only the Orc1-5 subunits are required for origin binding; Orc6 is essential for maintenance of pre-RCs once formed. Interactions within ORC suggest that Orc2-3-6 may form a core complex.
A schematic of the loading of the eukaryotic pre-replication complex.
original antigenic sin
Original antigenic sin, also known as antigenic imprinting or the Hoskins effect, refers to the propensity of the body's immune system to preferentially utilize immunological memory based on a previous infection when a second slightly different version of that foreign pathogen (e.g. a virus or bacterium) is encountered. This leaves the immune system "trapped" by the first response it has made to each antigen, and unable to mount potentially more effective responses during subsequent infections. Antibodies or T-cells induced during infections with the first variant of the pathogen are subject to a form of original antigenic sin, termed repertoire freeze.
This phenomenon was first described in 1960 by Thomas Francis, Jr. in the article "On the Doctrine of Original Antigenic Sin". It is named by analogy to the theological concept of original sin. According to Thomas Francis, who originally described the idea, and cited by Richard Krause:
"The antibody of childhood is largely a response to dominant antigen of the virus causing the first type A influenza infection of the lifetime. [...] The imprint established by the original virus infection governs the antibody response thereafter. This we have called the Doctrine of the Original Antigenic Sin." (W)
Diagram explaining the Original Antigenic Sin hypothesis.
The original antigenic sin: When the body first encounters an infection it produces effective antibodies against its dominant antigens and thus eliminates the infection. But when it encounters the same infection, at a later evolved stage, with a new dominant antigen, with the original antigen now being recessive, the immune system will still produce the former antibodies against this old "now recessive antigen" and not develop new antibodies against the new dominant one, this results in the production of ineffective antibodies and thus a weak immunity..
A high affinity memory B cell, specific for Virus A, is preferentially activated by a new strain, Virus A1, to produce antibodies that ineffectively bind to the A1 strain. The presence of these antibodies inhibits activation of a naive B cell that produces more effective antibodies against Virus A1. This effect leads to a diminished immune response against Virus A1, and heightens the potential for serious infection.
Original antigenic sin, descriptive diagram. en:Original antigenic sin refers to the propensity of the body's immune system to preferentially utilize immunological memory based on a previous infection when a second slightly different version of that foreign entity is encountered..
Oxidative phosphorylation or electron transport-linked phosphorylation) is the metabolic pathway in whichcells use enzymes to oxidizenutrients, thereby releasing the chemical energy stored within in order to produce adenosine triphosphate (ATP). In most eukaryotes, this takes place inside mitochondria. Almost all aerobic organisms carry out oxidative phosphorylation. This pathway is so pervasive because the energy of the double bond of oxygen is so much higher than the energy of the double bond in carbon dioxide or in pairs of single bonds in organic molecules observed in alternative fermentation processes such as anaerobicglycolysis.
During oxidative phosphorylation, electrons are transferred from electron donors to electron acceptors such as oxygen in redox reactions. These redox reactions release the energy stored in the relatively weak double bond of O2, which is used to form ATP. In eukaryotes, these redox reactions are catalyzed by a series of protein complexes within the inner membrane of the cell's mitochondria, whereas, in prokaryotes, these proteins are located in the cell's intermembrane space. These linked sets of proteins are called electron transport chains. In eukaryotes, five main protein complexes are involved, whereas in prokaryotes many different enzymes are present, using a variety of electron donors and acceptors. (W)
Complex I or NADH-Q oxidoreductase. The abbreviations are discussed in the text. In all diagrams of respiratory complexes in this article, the matrix is at the bottom, with the intermembrane space above.
Oxidative stress reflects an imbalance between the systemic manifestation of reactive oxygen species and a biological system's ability to readily detoxify the reactive intermediates or to repair the resulting damage. Disturbances in the normal redox state of cells can cause toxic effects through the production of peroxides and free radicals that damage all components of the cell, including proteins,lipids, and DNA. Oxidative stress from oxidative metabolism causes base damage, as well as strand breaks in DNA. Base damage is mostly indirect and caused by reactive oxygen species (ROS) generated, e.g. O2- (superoxide radical), OH (hydroxyl radical) and H2O2 (hydrogen peroxide). Further, some reactive oxidative species act as cellular messengers in redox signaling. Thus, oxidative stress can cause disruptions in normal mechanisms of cellular signaling.
Oxidative stress mechanisms in tissue injury. Free radical toxicity induced by xenobiotics and the subsequent detoxification by cellular enzymes (termination).
p
P element
P elements are transposable elements that were discovered in Drosophila as the causative agents of genetic traits called hybrid dysgenesis. The transposon is responsible for the P trait of the P element and it is found only in wild flies. They are also found in many other eukaryotes.
The P element encodes for the protein P transposase. Unlike laboratory strain females, wild type females are thought also to express an inhibitor to P transposase function, from the very same element. This inhibitor reduces the disruption to the genome caused by the P elements, allowing fertile progeny. Evidence for this comes from crosses of laboratory females (which lack P transposase inhibitor) with wild type males (which have P elements). In the absence of the inhibitor, the P elements can proliferate throughout the genome, disrupting many genes and killing progeny.
P elements are commonly used as mutagenic agents in genetic experiments with Drosophila. One advantage of this approach is that the mutations are easy to locate. In hybrid dysgenesis, one strain of Drosophila mates with another strain of Drosophila producing hybrid offspring and causing chromosomal damage known to be dysgenic. Hybrid dysgenesis requires a contribution from both parents. For example, in the P-M system, where the P strain contributes paternally and M strain contributes maternally, dysgenesis can occur. The reverse cross, with M cytotype father and P mother, produces normal offspring, as it crosses in a P x P or M x M manner. P male chromosomes can cause dysgenesis when crossed with an M female. (W)
P-glycoproteinP-glycoprotein 1 (permeability glycoprotein, abbreviated as P-gp or Pgp) also known as multidrug resistance protein 1 (MDR1) or ATP-binding cassette sub-family B member 1 (ABCB1) or cluster of differentiation 243 (CD243) is an important protein of the cell membrane that pumps many foreign substances out of cells. More formally, it is an ATP-dependent efflux pump with broad substrate specificity. It exists in animals, fungi, and bacteria, and it likely evolved as a defense mechanism against harmful substances. (W)
Structure of the mouse P-glycoprotein based on the 3g5u PDB coordinates.
palindromic sequence
A palindromic sequence is a nucleic acid sequence in a double-stranded DNA or RNA molecule wherein reading in a certain direction (e.g. 5' to 3') on one strand matches the sequence reading in the same direction (e.g. 5' to 3') on the complementary strand. This definition of palindrome thus depends on complementary strands being palindromic of each other.
The meaning of palindrome in the context of genetics is slightly different from the definition used for words and sentences. Since a double helix is formed by two paired antiparallel strands of nucleotides that run in opposite directions, and the nucleotides always pair in the same way (adenine (A) with thymine (T) in DNA or uracil (U) in RNA; cytosine (C) with guanine (G)), a (single-stranded) nucleotide sequence is said to be a palindrome if it is equal to its reverse complement. For example, the DNA sequence ACCTAGGT is palindromic because its nucleotide-by-nucleotide complement is TGGATCCA, and reversing the order of the nucleotides in the complement gives the original sequence. (W)
Palindrome of DNA structure A: Palindrome, B: Loop, C: Stem.
pannexin
Pannexins (from Greek 'παν' — all, and from Latin 'nexus' — connection) are a family of vertebrate proteins identified by their homology to the invertebrate innexins. While innexins are responsible for forming gap junctions in invertebrates, the pannexins have been shown to predominantly exist as large transmembrane channels connecting the intracellular and extracellular space, allowing the passage of ions and small molecules between these compartments (such as ATP and sulforhodamine B).
Three pannexins have been described in Chordates: Panx1, Panx2 and Panx3. (W)
Simplified illustration of extracellular purinergic signalling.
paracrine signaling
Paracrine signaling is a form of cell signaling or cell-to-cell communication in which a cell produces a signal to induce changes in nearby cells, altering the behaviour of those cells. Signaling molecules known as paracrine factors diffuse over a relatively short distance (local action), as opposed to cell signaling by endocrine factors, hormones which travel considerably longer distances via the circulatory system;juxtacrine interactions; and autocrine signaling. Cells that produce paracrine factors secrete them into the immediate extracellular environment. Factors then travel to nearby cells in which the gradient of factor received determines the outcome. However, the exact distance that paracrine factors can travel is not certain.
Although paracrine signaling elicits a diverse array of responses in the induced cells, most paracrine factors utilize a relatively streamlined set of receptors and pathways. In fact, different organs in the body - even between different species - are known to utilize a similar sets of paracrine factors in differential development. The highly conserved receptors and pathways can be organized into four major families based on similar structures: fibroblast growth factor (FGF) family, Hedgehog family, Wnt family, and TGF-β superfamily. Binding of a paracrine factor to its respective receptor initiates signal transduction cascades, eliciting different responses. (W)
Overview of signal transduction pathways.
Diagram showing key components of a signal transduction pathway. See the MAPK/ERK pathway article for details.
Phenotype and survival of mice after knockout of some Jak or STAT genes:
The part of the antigen to which the paratope binds is called an epitope. This can be mimicked by a mimotope. The figure given on the right hand side depicts the antibody commonly found on a B leukocyte. The engraved inner portions of idiotype (encircled region no.5 in the above diagram) is the paratope where the epitope of the antigen binds. (W)
Schematic diagram of the basic unit of immunoglobulin (antibody) Fab Fc heavy chain (consist of VH, CH1, hinge, CH2 and CH3 regions: from N-term) light chain (consist of VL and CL regions: from N-term) antigen binding site hinge regions (*) -S-S- mean disulfide bonds.
passive transportPassive transport is a movement of ions and other atomic or molecular substances across cell membranes without need of energy input. Unlike active transport, it does not require an input of cellular energy because it is instead driven by the tendency of the system to grow in entropy. The rate of passive transport depends on the permeability of the cell membrane, which, in turn, depends on the organization and characteristics of the membrane lipids and proteins. The four main kinds of passive transport are simple diffusion, facilitated diffusion, filtration, and/or osmosis. (W)
B___.
Passive diffusion on a cell membrane.
Simple diffusion, the movement of particles from an area where their concentration is high to an area that has low concentration. one of the diferent ways in wich molecules move in cells..
Depiction of facilitated diffusion.
Filtration is the process of using a filter to mechanically separate a mixture.
Effect of osmosis on blood cells under different solutions.
Osmotic pressure is the hydrostatic pressure produced by a solution in a space divided by a differentially permeable membrane due to a differential in the concentrations of solute.
It is one of three principal proteases in the human digestive system, the other two being chymotrypsin and trypsin. During the process of digestion, these enzymes, each of which is specialized in severing links between particular types of amino acids, collaborate to break down dietary proteins into their components, i.e., peptides and amino acids, which can be readily absorbed by the small intestine. The cleavage specificity of pepsin is broad, but some amino acids like tyrosine,phenylalanine and tryptophan increase the probability of cleavage.
When a polypeptide contains more than fifty amino acids it is known as a protein. Proteins consist of one or more polypeptides arranged in a biologically functional way, often bound to ligands such as coenzymes and cofactors, or to another protein or other macromolecule such as DNA or RNA, or to complex macromolecular assemblies.
Amino acids that have been incorporated into peptides are termed residues. A water molecule is released during formation of each amide bond. All peptides except cyclic peptides have an N-terminal (amine group) and C-terminal (carboxyl group) residue at the end of the peptide (as shown for the tetrapeptide in the image). (W)
It can also be called an eupeptide bond to separate it from an isopeptide bond, a different type of amide bond between two amino acids.
Synthesis
When two amino acids form a dipeptide through a peptide bond it is a type of condensation reaction. In this kind of condensation, two amino acids approach each other, with the non-side chain (C1) carboxylic acidmoiety of one coming near the non-side chain (N2) amino moiety of the other. One loses a hydrogen and oxygen from its carboxyl group (COOH) and the other loses a hydrogen from its amino group (NH2). This reaction produces a molecule of water (H2O) and two amino acids joined by a peptide bond (-CO-NH-). The two joined amino acids are called a dipeptide.
The amide bond is synthesized when the carboxyl group of one amino acid molecule reacts with the amino group of the other amino acid molecule, causing the release of a molecule of water (H2O), hence the process is a dehydration synthesis reaction.
The formation of the peptide bond consumes energy, which, in organisms, is derived from ATP. Peptides and proteins are chains of amino acids held together by peptide bonds (and sometimes by a few isopeptide bonds). Organisms use enzymes to produce nonribosomal peptides, and ribosomes to produce proteins via reactions that differ in details from dehydration synthesis.
Some peptides, like alpha-amanitin, are called ribosomal peptides as they are made by ribosomes, but many are nonribosomal peptides as they are synthesized by specialized enzymes rather than ribosomes. For example, the tripeptide glutathione is synthesized in two steps from free amino acids, by two enzymes: glutamate–cysteine ligase (forms an isopeptide bond, which is not a peptide bond) and glutathione synthetase (forms a peptide bond).
Degradation
A peptide bond can be broken by hydrolysis (the addition of water). In the presence of water they will break down and release 8–16 kilojoule/mol (2–4 kcal/mol) of Gibbs energy. This process is extremely slow, with the half life at 25 °C of between 350 and 600 years per bond.
In living organisms, the process is normally catalyzed by enzymes known as peptidases or proteases, although there are reports of peptide bond hydrolysis caused by conformational strain as the peptide/protein folds into the native structure. This non-enzymatic process is thus not accelerated by transition state stabilization, but rather by ground state destabilization.
peptide computing
Peptide computing is a form of computing which uses peptides and molecular biology, instead of traditional silicon-based computer technologies. The basis of this computational model is the affinity of antibodies towards peptide sequences. Similar to DNA computing, the parallel interactions of peptide sequences and antibodies have been used by this model to solve a few NP-complete problems. Specifically, the hamiltonian path problem (HPP) and some versions of the set cover problem are a few NP-complete problems which have been solved using this computational model so far. This model of computation has also been shown to be computationally universal (or Turing complete).
This model of computation has some critical advantages over DNA computing. For instance, while DNA is made of four building blocks, peptides are made of twenty building blocks. The peptide-antibody interactions are also more flexible with respect to recognition and affinity than an interaction between a DNA strand and its reverse complement. However, unlike DNA computing, this model is yet to be practically realized. The main limitation is the availability of specific monoclonal antibodies required by the model. (W)
peptide synthesis
In organic chemistry,peptide synthesis is the production of peptides, compounds where multiple amino acids are linked via amide bonds, also known as peptide bonds. Peptides are chemically synthesized by the condensation reaction of the carboxyl group of one amino acid to the amino group of another. Protecting group strategies are usually necessary to prevent undesirable side reactions with the various amino acid side chains. Chemical peptide synthesis most commonly starts at the carboxyl end of the peptide (C-terminus), and proceeds toward the amino-terminus (N-terminus). Protein biosynthesis (long peptides) in living organisms occurs in the opposite direction. (W)
Coupling of two amino acids in solution. The unprotected amine of one reacts with the unprotected carboxylic acid group of the other to form a peptide bond. In this example, the second reactive group (amine/acid) in each of the starting materials bears a protecting group.
A. Perineuronal nets are made of chondroitin sulfate proteoglycans (CSPGs). Here, the CSPGs neurocan, versican, brevican, and aggrecan are noncovalently bonded to hyaluronan. Associations occur between other CSPGs through tenascin (T, triangles). Tenascin, in turn, binds to CS glycosaminoglycans (red lines) as well as cell surface CSPGs. Phosphacan can also bind to cell surface receptors such as NCAM. B. Application of chondroitinase ABC (ChABC) degrades all the CS glycosaminoglycans (red lines) as well as hyaluronan (pink line), causing major disruptions in the structure of the perineuronal net. These disruptions may allow axons to penetrate the vacated space and permit restoration of neural plasticity.
pH
In chemistry,pH (denoting 'potential of hydrogen' or 'power of hydrogen') is a scale used to specify the acidity or basicity of an aqueous solution. Lower pH values correspond to solutions which are more acidic in nature, while higher values correspond to solutions which are more basic or alkaline. At room temperature (25°C or 77°F), pure water is neutral (neither acidic nor basic) and therefore has a pH of 7.
The pH scale is logarithmic and inversely indicates the concentration of hydrogen ions in the solution (a lower pH indicates a higher concentration of hydrogen ions). This is because the formula used to calculate pH approximates the negative of the base 10 logarithm of the molar concentrationof hydrogen ions in the solution. More precisely, pH is the negative of the base 10 logarithm of the activity of the hydrogen ion.
At 25 °C, solutions with a pH less than 7 are acidic, and solutions with a pH greater than 7 are basic. The neutral value of the pH depends on the temperature, being lower than 7 if the temperature increases. The pH value can be less than 0 for very strong acids, or greater than 14 for very strong bases.
The pH scale is traceable to a set of standard solutions whose pH is established by international agreement. Primary pH standard values are determined using a concentration cell with transference, by measuring the potential difference between a hydrogen electrode and a standard electrode such as the silver chloride electrode. The pH of aqueous solutions can be measured with a glass electrode and a pH meter, or a color-changing indicator. Measurements of pH are important in chemistry, agronomy, medicine, water treatment, and many other applications. (W)
The phosphate or orthophosphate ion [PO4]3− is derived from phosphoric acid by the removal of three protons H+. Removal of one or two protons gives the dihydrogen phosphate ion [H2PO4]−2 and the hydrogen phosphate ion [HPO4]2− ion, respectively. These names are also used for salts of those anions, such as ammonium dihydrogen phosphate and trisodium phosphate.
In organic chemistry,phosphate or orthophosphate is an organophosphate, an ester of orthophosphoric acid of the form PO4RR′R″ where one or more hydrogen atoms are replaced by organic groups. An example is trimethyl phosphate, (CH3)3PO4. The term also refers to the trivalent functional group OP(O-)3 in such esters.
phosphatome
The phosphatome of an organism is the set of phosphatase genes in its genome. Phosphatases are enzymes that catalyze the removal of phosphate from biomolecules. Over half of all cellular proteins are modified by phosphorylation which typically controls their functions. Protein phosphorylation is controlled by the opposing actions of protein phosphatases and protein kinases. Most phosphorylation sites are not linked to a specific phosphatase, so the phosphatome approach allows a global analysis of dephosphorylation, screening to find the phosphatase responsible for a given reaction, and comparative studies between different phosphatases, similar to how protein kinase research has been impacted by the kinome approach.(W)
phosphodiester bond
A phosphodiester bond occurs when exactly two of the hydroxyl groups in phosphoric acid react with hydroxyl groups on other molecules to form two ester bonds.
The phosphate groups in the phosphodiester bond are negatively charged. Because the phosphate groups have a pKa near 0, they are negatively charged at pH 7. This repulsion forces the phosphates to take opposite sides of the DNA strands and is neutralized by proteins (histones), metal ions such as magnesium, and polyamines.
In order for the phosphodiester bond to be formed and the nucleotides to be joined, the tri-phosphate or di-phosphate forms of the nucleotide building blocks are broken apart to give off energy required to drive the enzyme-catalyzed reaction. When a single phosphate or two phosphates known as pyrophosphates break away and catalyze the reaction, the phosphodiester bond is formed.
Hydrolysis of phosphodiester bonds can be catalyzed by the action of phosphodiesterases which play an important role in repairing DNA sequences.
Phospholipids are a key component of all cell membranes. They can form lipid bilayers because of their amphiphilic characteristic. In eukaryotes, cell membranes also contain another class of lipid, sterol, interspersed among the phospholipids. The combination provides fluidity in two dimensions combined with mechanical strength against rupture. Purified phospholipids are produced commercially and have found applications in nanotechnology and materials science.
Serine in an amino acid chain, before and after phosphorylation.
PIN domain
In molecular biology the PIN domain is a protein domain that is about 130 amino acids in length. PIN domains function as nuclease enzymes that cleave single stranded RNA in a sequence- or structure-dependent manner.
PIN domains contain four nearly invariant acidic residues. Crystal structures show these residues clustered together in the putative active site. In eukaryotes PIN domains are found in proteins involved in nonsense mediated mRNA decay, in proteins such as SMG5 and SMG6, and in processing of 18S ribosomal RNA. The majority of PIN-domain proteins found in prokaryotes are the toxic components of toxin-antitoxin operons. These loci provide a control mechanism that helps free-living prokaryotes cope with nutritional stress. (W)
Cartoon representation of the molecular structure of protein registered with 1o4w code.
Crystal structure of PIN (PilT N-terminus) domain (AF0591) from Archaeoglobus fulgidus at 1.90 Angstrom resolution. 1o4w
pinocytosis
In cellular biology, pinocytosis, otherwise known as fluid endocytosis and bulk-phase pinocytosis, is a mode of endocytosis in which small particles suspended in extracellular fluid are brought into the cell through an invagination of the cell membrane, resulting in a suspension of the particles within a small vesicle inside the cell. These pinocytotic vesicles then typically fuse with early endosomes to hydrolyze (break down) the particles.
Pinocytosis is further segregated into the pathways macropinocytosis, clathrin-mediated endocytosis, caveolin-mediated endocytosis, or clathrin- and caveolin-independent endocytosis, all of which differ by the mechanism of vesicle formation as well as the resulting size of these vesicles.
Pinocytosis is variably subdivided into categories depending on molecular mechanism and the fate of the internalized molecules. Pinocytosis is, in some cases, considered to be a constitutive process, while in others it is receptor-mediated and highly regulated. (W)
Pinocytosis.
Pinocytosis is a form of endocytosis, in which small particles are taken in by a cell by splitting into smaller particles. The particles then form small vesicles which subsequently fuse with lysosomes to hydrolyze, or to break down, the particles.
PiwiPiwi (or PIWI) genes were identified as regulatoryproteins responsible for stem cell and germ celldifferentiation. Piwi is an abbreviation of P-elementInduced WImpy testis in Drosophila. Piwi proteins are highly conservedRNA-binding proteins and are present in both plants and animals. Piwi proteins belong to the Argonaute/Piwi family and have been classified as nuclear proteins. Studies on Drosophila have also indicated that Piwi proteins have slicer activity conferred by the presence of the Piwi domain. In addition, Piwi associates with heterochromatin protein 1, an epigenetic modifier, and piRNA-complementary sequences. These are indications of the role Piwi plays in epigenetic regulation. Piwi proteins are also thought to control the biogenesis of piRNA as many Piwi-like proteins contain slicer activity which would allow Piwi proteins to process precursor piRNA into mature piRNA.(W)
All human Piwi proteins and argonaute proteins have the same RNA binding domains, PAZ and Piwi.
Piwi-piRNA interactions: Within the nucleus, this pathway is involved in DNA methylation (A), histone methylation of H3K9 through interactions with heterochromatin protein 1 (HP1) and H3K9 histone methyltransferase (B). The Piwi-piRNA pathway also interacts with the elF translational initiator (C).
Piwi-piRNA interactions: Within the nucleus, this pathway is involved in DNA methylation (A) and histone methylation of H3K9 through interactions with heterochromatin protein 1 (HP1) and H3K9 histone methyltransferase (B). The Piwi-piRNA pathway also interacts with the elF translational initiator (C). Modified from Lindse K, 2013
piwi-interacting RNA (piRNA)
Piwi-interacting RNA (piRNA) is the largest class of small non-codingRNA molecules expressed in animal cells. piRNAs form RNA-protein complexes through interactions with piwi-subfamily Argonaute proteins. These piRNA complexes are mostly involved in the epigenetic and post-transcriptional silencing of transposable elements and other spurious or repeat-derived transcripts, but can also be involved in the regulation of other genetic elements in germ line cells.
piRNAs are mostly created from loci that function as transposon traps which provide a kind of RNA-mediated adaptive immunity against transposon expansions and invasions. They are distinct from microRNA (miRNA) in size (26–31 nucleotides as opposed to 21–24 nt), lack of sequence conservation, increased complexity, and independence of Dicer for biogenesis, at least in animals. (Plant Dcl2 may play a role in rasi/piRNA biogenesis.)
Double-stranded RNAs capable of silencing repeat elements, then known as repeat associated small interfering RNA (rasiRNA), were proposed in Drosophila in 2001. By 2008, it was still unclear how piRNAs are generated, but potential methods had been suggested, and it was certain their biogenesis pathway is distinct from miRNA and siRNA, while rasiRNA is now considered a piRNA subspecies. (W)
Proposed piRNA structure, with the 3′ end 2′-O-methylation.
The ping-pong mechanism for the biogenesis of the 5′ end of rasiRNA.
ploidy
Ploidy is the number of complete sets of chromosomes in a cell, and hence the number of possible alleles for autosomal and pseudoautosomalgenes.Somatic cells,tissues, and individual organisms can be described according to the number of sets of chromosomes present (the "ploidy level"): monoploid (1 set), diploid (2 sets), triploid (3 sets), tetraploid (4 sets), pentaploid (5 sets), hexaploid (6 sets), heptaploid or septaploid (7 sets), etc. The generic term polyploid is often used to describe cells with three or more chromosome sets. (W)
A haploid set that consists of a single complete set of chromosomes (equal to the monoploid set), as shown in the picture above, must belong to a diploid species. If a haploid set consists of two sets, it must be of a tetraploid (four sets) species.
poly(A)-binding proteinPoly(A)-binding protein (PAB or PABP) is a RNA-binding protein which triggers the binding of eukaryotic initiation factor 4 complex (eIF4G) directly to the poly(A) tail of mRNA. The poly(A) tail is located on the 3' end of mRNA and is 200-250 nucleotides long. The binding protein is also involved in mRNA precursors by helping polyadenylate polymerase add the poly(A) nucleotide tail to the pre-mRNA before translation. The nuclear isoform selectively binds to around 50 nucleotides and stimulates the activity of polyadenylate polymerase by increasing its affinity towards RNA. Poly(A)-binding protein is also present during stages of mRNA metabolism including nonsense-mediated decay and nucleocytoplasmic trafficking. The poly(A)-binding protein may also protect the tail from degradation and regulate mRNA production. Without these two proteins in-tandem, then the poly(A) tail would not be added and the RNA would degrade quickly. (W)
Poly(A) RNA binding protein PABP (PDB 1CVJ).
RRM 1 and 2 connected by a short linker showing binding to the polyadenylate RNA.
Cellular vs rotavirus translation.
polyadenylation
Polyadenylation is the addition of a poly(A) tail to a messenger RNA. The poly(A) tail consists of multiple adenosine monophosphates; in other words, it is a stretch of RNA that has only adenine bases. In eukaryotes, polyadenylation is part of the process that produces mature messenger RNA (mRNA) for translation. In many bacteria, the poly(A) tail promotes degradation of the mRNA. It, therefore, forms part of the larger process of gene expression.
The process of polyadenylation begins as the transcription of a geneterminates. The 3′-most segment of the newly made pre-mRNA is first cleaved off by a set of proteins; these proteins then synthesize the poly(A) tail at the RNA's 3′ end. In some genes these proteins add a poly(A) tail at one of several possible sites. Therefore, polyadenylation can produce more than one transcript from a single gene (alternative polyadenylation), similar to alternative splicing.
The poly(A) tail is important for the nuclear export, translation, and stability of mRNA. The tail is shortened over time, and, when it is short enough, the mRNA is enzymatically degraded. However, in a few cell types, mRNAs with short poly(A) tails are stored for later activation by re-polyadenylation in the cytosol. In contrast, when polyadenylation occurs in bacteria, it promotes RNA degradation. This is also sometimes the case for eukaryotic non-coding RNAs.
mRNA molecules in both prokaryotes and eukaryotes have polyadenylated 3′-ends, with the prokaryotic poly(A) tails generally shorter and less mRNA molecules polyadenylated. (W)
Typical structure of a mature eukaryotic mRNA.
Diagramatic structure of a typical human protein coding mRNA including the untranslated regions (UTRs).It is drawn approximately to scale. The cap is only one modified base, average en:5' UTR length 170, en:3' UTR 700. Reproduced from http://commons.wikimedia.org/wiki/Image:MRNA_structure.png
Chemical structure of RNA. The sequence of bases differs between RNA molecules.
polyclonal antibodiesPolyclonal antibodies (pAbs) are antibodies that are secreted by different B cell lineages within the body (whereas monoclonal antibodies come from a single cell lineage). They are a collection of immunoglobulin molecules that react against a specific antigen, each identifying a different epitope. (W)
polyclonal B cell response
Polyclonal B cell response is a natural mode of immune response exhibited by the adaptive immune system of mammals. It ensures that a single antigen is recognized and attacked through its overlapping parts, called epitopes, by multiple clones of B cell.
In the course of normal immune response, parts of pathogens (e.g. bacteria) are recognized by the immune system as foreign (non-self), and eliminated or effectively neutralized to reduce their potential damage. Such a recognizable substance is called an antigen. The immune system may respond in multiple ways to an antigen; a key feature of this response is the production of antibodies by B cells (or B lymphocytes) involving an arm of the immune system known as humoral immunity. The antibodies are soluble and do not require direct cell-to-cell contact between the pathogen and the B-cell to function. (W)
Polyclonal response by B cells against linear epitopes.
Examples of substances recognized as foreign (non-self).
Schematic diagram to explain mechanisms of clonal selection of B cell.
Selection of a clone of B cells that most selectively binds with an antigen followed by proliferation and production of soluble antibodies by differentiated plasma cells. (W).
Steps in production of antibodies by B cells:1. Antigen is recognized and engulfed by B cell 2. Antigen is processed 3. Processed antigen is presented on B cell surface 4. B cell and T cell mutually activate each other 5. B cells differentiate into plasma cells to produce soluble antibodies.
Recognition of conformational epitopes by B cells. Segments widely separated in the primary structure have come in contact in the three-dimensional tertiary structure forming part of the same epitope.
Steps of a macrophage ingesting a pathogen.
The clone 1 that got stimulated by first antigen gets stimulated by second antigen, too, which best binds with naive cell of clone 2. However, antibodies produced by plasma cells of clone 1 inhibit the proliferation of clone 2.
The term "polymer" derives from the Greek word πολύς (polus, meaning “many, much”) and μέρος (meros, meaning “part”), and refers to a molecule whose structure is composed of multiple repeating units, from which originates a characteristic of high relative molecular mass and attendant properties. The units composing polymers derive, actually or conceptually, from molecules of low relative molecular mass. The term was coined in 1833 by Jöns Jacob Berzelius, though with a definition distinct from the modern IUPAC definition. The modern concept of polymers as covalently bonded macromolecular structures was proposed in 1920 by Hermann Staudinger, who spent the next decade finding experimental evidence for this hypothesis.
Polymers are studied in the fields of biophysics and macromolecular science, and polymer science (which includes polymer chemistry and polymer physics). Historically, products arising from the linkage of repeating units by covalentchemical bonds have been the primary focus of polymer science; emerging important areas of the science now focus on non-covalent links. Polyisoprene of latexrubber is an example of a biological polymer, and the polystyrene of styrofoam is an example of a synthetic polymer. In biological contexts, essentially all biological macromolecules—i.e., proteins (polyamides), nucleic acids (polynucleotides), and polysaccharides—are purely polymeric, or are composed in large part of polymeric components—e.g., isoprenylated or lipid-modified glycoproteins, where small lipidic molecules and oligosaccharide modifications occur on the polyamide backbone of the protein.
The simplest theoretical models for polymers are ideal chains.
polymerase
A polymerase is an enzyme (EC 2.7.7.6/7/19/48/49) that synthesizes long chains of polymers or nucleic acids.DNA polymerase and RNA polymerase are used to assemble DNA and RNA molecules, respectively, by copying a DNA template strand using base-pairing interactions or RNA by half ladder replication.
A polymerase may be template dependent or template independent. Poly-A-polymerase is an example of template independent polymerase. Terminal deoxynucleotidyl transferase also known to have template independent and template dependent activities.
Reverse transcriptase, an enzyme used by RNAretroviruses like HIV, which is used to create a complementary strand to the preexisting strand of viral RNA before it can be integrated into the DNA of the hostcell. It is also a major target for antiviral drugs.
polymerase chain reaction (PCR)Polymerase chain reaction (PCR) is a method widely used to rapidly make millions to billions of copies of a specific DNA sample, allowing scientists to take a very small sample of DNA and amplify it to a large enough amount to study in detail. PCR was invented in 1984 by the AmericanbiochemistKary Mullis at Cetus Corporation. It is fundamental to much of genetic testing including analysis of ancient samples of DNA and identification of infectious agents. Using PCR, copies of very small amounts of DNA sequences are exponentially amplified in a series of cycles of temperature changes. PCR is now a common and often indispensable technique used in medical laboratory and clinical laboratory research for a broad variety of applications including biomedical research and criminal forensics(W)
Schematic drawing of a complete PCR cycle.
This is a visualization of Exponential Amplification to give a better understanding of what it is and why it is so important in the PCR process. Showing how it makes copies of the sample collected at the scene.
polynucleotide phosphorylasePolynucleotide Phosphorylase (PNPase) is a bifunctional enzyme with a phosphorolytic 3' to 5' exoribonuclease activity and a 3'-terminal oligonucleotidepolymerase activity. That is, it dismantles the RNA chain starting at the 3' end and working toward the 5' end. It also synthesizes long, highly heteropolymeric tails in vivo. It accounts for all of the observed residual polyadenylation in strains of Escherichia coli missing the normal polyadenylation enzyme. Discovered by Marianne Grunberg-Manago working in Severo Ochoa's lab in 1955, the RNA-polymerization activity of PNPase was initially believed to be responsible for DNA-dependent synthesis of messenger RNA, a notion that got disproved by the late 1950s. (W)
Crystal structure 1E3P.
polyphosphatePolyphosphates are salts or esters of polymeric oxyanions formed from tetrahedral PO4 (phosphate) structural units linked together by sharing oxygen atoms. Polyphosphates can adopt linear or a cyclic ring structures. In biology, the polyphosphate esters ADP and ATP are involved in energy storage. A variety of polyphosphates find application in mineral sequestration in municipal waters, generally being present at 1 to 5 ppm. GTP,CTP, and UTP are also nucleotides important in the protein synthesis, lipid synthesis, and carbohydrate metabolism, respectively. Polyphosphates are also used as food additives, marked E452. (W)
population bottleneck
A population bottleneck or genetic bottleneck is a sharp reduction in the size of a population due to environmental events such as famines, earthquakes, floods, fires, disease, and droughts or human activities such as genocide and human population planning. Such events can reduce the variation in the gene pool of a population; thereafter, a smaller population, with a smaller genetic diversity, remains to pass on genes to future generations of offspring through sexual reproduction. Genetic diversity remains lower, increasing only when gene flow from another population occurs or very slowly increasing with time as random mutations occur. This results in a reduction in the robustness of the population and in its ability to adapt to and survive selecting environmental changes, such as climate change or a shift in available resources. Alternatively, if survivors of the bottleneck are the individuals with the greatest genetic fitness, the frequency of the fitter genes within the gene pool is increased, while the pool itself is reduced.(W)
Population bottleneck followed by recovery or extinction.
post-transcriptional modification
Post-transcriptional modification or co-transcriptional modification is a set of biological processes common to most eukaryotic cells by which an RNAprimary transcript is chemically altered following transcription from a gene to produce a mature, functional RNA molecule that can then leave the nucleus and perform any of a variety of different functions in the cell. There are many types of post-transcriptional modifications achieved through a diverse class of molecular mechanisms.
One example is the conversion of precursor messenger RNA transcripts into mature messenger RNA that is subsequently capable of being translated into protein. This process includes three major steps that significantly modify the chemical structure of the RNA molecule: the addition of a 5' cap, the addition of a 3' polyadenylated tail, and RNA splicing. Such processing is vital for the correct translation of eukaryotic genomes because the initial precursor mRNA produced by transcription often contains both exons (coding sequences) and introns (non-coding sequences); splicing removes the introns and links the exons directly, while the cap and tail facilitate the transport of the mRNA to a ribosome and protect it from molecular degradation.
Post-transcriptional modifications may also occur during the processing of other transcripts which ultimately become transfer RNA,ribosomal RNA, or any of the other types of RNA used by the cell. (W)
post-transcriptional regulationPost-transcriptional regulation is the control of gene expression at the RNA level, therefore between the transcription and the translation of the gene. It contributes substantially to gene expression regulation across human tissues.
After being produced, the stability and distribution of the different transcripts is regulated (post-transcriptional regulation) by means of RNA binding protein (RBP) that control the various steps and rates controlling events such as alternative splicing, nuclear degradation (exosome), processing, nuclear export (three alternative pathways), sequestration in P-bodies for storage or degradation and ultimately translation. These proteins achieve these events thanks to an RNA recognition motif (RRM) that binds a specific sequence or secondary structure of the transcripts, typically at the 5’ and 3’ UTR of the transcript. In short, the dsRNA sequences, which will be broken down into siRNA inside of the organism, will match up with the RNA to inhibit the gene expression in the cell.
Modulating the capping, splicing, addition of a Poly(A) tail, the sequence-specific nuclear export rates and in several contexts sequestration of the RNA transcript occurs in eukaryotes but not in prokaryotes. This modulation is a result of a protein or transcript which in turn is regulated and may have an affinity for certain sequences.
Capping changes the five prime end of the mRNA to a three prime end by 5'-5' linkage, which protects the mRNA from 5' exonuclease, which degrades foreign RNA. The cap also helps in ribosomal binding.
RNA splicing removes the introns, noncoding regions that are transcribed into RNA, in order to make the mRNA able to create proteins. Cells do this by spliceosomes binding on either side of an intron, looping the intron into a circle and then cleaving it off. The two ends of the exons are then joined together.
Addition of poly(A) tail otherwise known as polyadenylation. That is, a stretch of RNA that is made solely of adenine bases is added to the 3' end, and acts as a buffer to the 3' exonuclease in order to increase the half life of mRNA. In addition, a long poly(A) tail can increase translation. Poly(A)-binding protein (PABP) binds to a long poly(A) tail and mediates the interaction between EIF4E and EIF4G which encourages the initiation of translation.
RNA editing is a process which results in sequence variation in the RNA molecule, and is catalyzed by enzymes. These enzymes include the adenosine deaminase acting on RNA (ADAR) enzymes, which convert specific adenosine residues to inosine in an mRNA molecule by hydrolytic deamination. Three ADAR enzymes have been cloned, ADAR1, ADAR2 and ADAR3, although only the first two subtypes have been shown to have RNA editing activity. Many mRNAs are vulnerable to the effects of RNA editing, including the glutamate receptor subunits GluR2, GluR3, GluR4, GluR5 and GluR6 (which are components of the AMPA and kainate receptors), the serotonin2C receptor, the GABA-alpha3 receptor subunit, the tryptophan hydroxylase enzyme TPH2, the hepatitis delta virus and more than 16% of microRNAs. In addition to ADAR enzymes, CDAR enzymes exist and these convert cytosines in specific RNA molecules, to uracil. These enzymes are termed 'APOBEC' and have genetic loci at 22q13, a region close to the chromosomal deletion which occurs in velocardiofacial syndrome (22q11) and which is linked to psychosis. RNA editing is extensively studied in relation to infectious diseases, because the editing process alters viral function.
mRNA Stability can be manipulated in order to control its half-life, and the poly(A) tail has some effect on this stability, as previously stated. Stable mRNA can have a half life of up to a day or more which allows for the production of more protein product; unstable mRNA is used in regulation that must occur quickly.
A prokaryotic example: Salmonella enterica (a pathogenic γ-proteobacterium) can express two alternative porins depending on the external environment (gut or murky water), this system involves EnvZ (osomotic sensor) which activates OmpR (transcription factor) which can bind to a high affinity promoter even at low concentrations and the low affinity promoter only at high concentrations (by definition): when the concentration of this transcription factor is high it activates OmpC and micF and inhibits OmpF, OmpF is further inhibited post-transcriptionally by micF RNA which binds to the OmpF transcript.
post-translational modification
Post-translational modification (PTM) refers to the covalent and generally enzymatic modification of proteins following protein biosynthesis. Proteins are synthesized by ribosomestranslatingmRNA into polypeptide chains, which may then undergo PTM to form the mature protein product. PTMs are important components in cell signaling, as for example when prohormones are converted to hormones.(W)
Post-translational modification of insulin. At the top, the ribosome translates a mRNA sequence into a protein, insulin, and passes the protein through the endoplasmic reticulum, where it is cut, folded and held in shape by disulfide (-S-S-) bonds. Then the protein passes through the golgi apparatus, where it is packaged into a vesicle. In the vesicle, more parts are cut off, and it turns into mature insulin.
potassium channelPotassium channels are the most widely distributed type of ion channel and are found in virtually all living organisms. They form potassium-selective pores that span cell membranes. Potassium channels are found in most cell types and control a wide variety of cell functions. (W)
Potassium channel Kv1.2, structure in a membrane-like environment. Calculated hydrocarbon boundaries of the lipid bilayer are indicated by red and blue lines.
Top view of a potassium channel with potassium ions (purple) moving through the pore (in the center). (PDB: 1BL8).
Crystallographic structure of the bacterial KcsA potassium channel (PDB: 1K4C). In this figure, only two of the four subunits of the tetramer are displayed for the sake of clarity. The protein is displayed as a green cartoon diagram. In addition backbone carbonyl groups and threonine sidechain protein atoms (oxygen = red, carbon = green) are displayed. Finally potassium ions (occupying the S2 and S4 sites) and the oxygen atoms of water molecules (S1 and S3) are depicted as purple and red spheres respectively.
1K4C structure of the KcsA K+ channel in complex with a monoclonal Fab antibody fragment.
Graphical representation of open and shut potassium channels (PDB: 1lnq and PDB: 1k4c). Two simple bacterial channels are shown to compare the "open" channel structure on the right with the "closed" structure on the left. At top is the filter (selects potassium ions), and at bottom is the gating domain (controls opening and closing of channel).
Open (at right) and shut (at left) of potassium channels, composed of two parts: filter (at top, select potassium) and gating domain (at bottom, control open and close of channel). From PDB file 1lnq, 1k4c, by David Goodsell in RCSB Molecule of the Month #38. (W)
pre-replication complex
A pre-replication complex (pre-RC) is a protein complex that forms at the origin of replication during the initiation step of DNA replication. Formation of the pre-RC is required for DNA replication to occur. Complete and faithful replication of the genome ensures that each daughter cell will carry the same genetic information as the parent cell. Accordingly, formation of the pre-RC is a very important part of the cell cycle.(W)
A simplified schematic of the loading of the eukaryotic pre-replication complex.
Overview of chromosome duplication in the cell cycle.
The chromosome is prepared for DNA duplication in G1, when prereplicative complexes are assembled at replication origins (red). Transformation of these complexes to preinitiation complexes and activation of the origin in S phase results in the unwinding of the DNA helix and initiation of DNA replication. Two replication forks move out from each origin until the entire chromosome is duplicated. Segregation of the duplicated chromosomes in M phase then results in two daughter cells with identical chromosomes. The activation of replication origins also causes disassembly of the prereplicative complex. Because new prereplicative complexes cannot be formed at origins until the following G1, each origin can be activated only once in each cell cycle. (W)
prenylation
Prenylation (also known as isoprenylation or lipidation) is the addition of hydrophobic molecules to a protein or chemical compound. It is usually assumed that prenyl groups (3-methylbut-2-en-1-yl) facilitate attachment to cell membranes, similar to lipid anchors like the GPI anchor, though direct evidence of this has not been observed. Prenyl groups have been shown to be important for protein–protein binding through specialized prenyl-binding domains. (W)
"Prenyl-" the functional group.
primary transcript
A primary transcript is the single-stranded ribonucleic acid (RNA) product synthesized by transcription of DNA, and processed to yield various mature RNA products such as mRNAs,tRNAs, and rRNAs. The primary transcripts designated to be mRNAs are modified in preparation for translation. For example, a precursor mRNA (pre-mRNA) is a type of primary transcript that becomes a messenger RNA (mRNA) after processing.
Pre-mRNA is synthesized from a DNA template in the cell nucleus by transcription. Pre-mRNA comprises the bulk of heterogeneous nuclear RNA (hnRNA). Once pre-mRNA has been completely processed, it is termed "mature messenger RNA", or simply "messenger RNA". The term hnRNA is often used as a synonym for pre-mRNA, although, in the strict sense, hnRNA may include nuclear RNA transcripts that do not end up as cytoplasmic mRNA. (W)
Pre-mRNA is the first form of RNA created through transcription in protein synthesis. The pre-mRNA lacks structures that the messenger RNA (mRNA) requires. First all introns have to be removed from the transcribed RNA through a process known as splicing. Before the RNA is ready for export, a Poly(A)tail is added to the 3' end of the RNA and a 5' cap is added to the 5' end..
Transcription of DNA by RNA polymerase to produce primary transcript.
Role of transcription factors and enhancers in gene expression regulation.
Alternative splicing of the primary transcript.
primaseDNA primase is an enzyme involved in the replication of DNA and is a type of RNA polymerase, Primase catalyzes the synthesis of a short RNA (or DNA in some organisms) segment called a primer complementary to a ssDNA (single-stranded DNA) template. After this elongation, the RNA piece is removed by a 5' to 3' exonuclease and refilled with DNA. (W)
Asymmetry in the synthesis of leading and lagging strands, with role of DNA primase shown.
Duplication of the DNA begins with origin unwinding, followed by the synthesis of RNA primers (jagged lines) on both DNA strands. DNA polymerase delta or epsilon extends these primers by adding new DNA (green lines) only in a 5' to 3' direction. On the leading strands, this results in the continuous synthesis of long DNA molecules. Lagging strands, in contrast, are synthesized discontinuously: primers are placed on the template every ~200 nucleotides and extended to form short Okazaki fragments. For simplicity, this diagram does not show the replacement of primers with DNA or the synthesis of telomeres at the chromosome ends .
Steps in DNA synthesis, with role of DNA primase shown.
This diagram shows the synthesis of an Okazaki fragment on the lagging strand; synthesis on the leading strand is not shown but involves the same steps. (a) Helicase unwinds the DNA helix, and the resulting single-stranded DNA is coated with RPA proteins. (b) The polymerase alpha–primase synthesizes a short RNA–DNA primer in the 5' to 3' direction, displacing RPA molecules as it travels along the template. (c) Following completion of the primer, the clamp loader displaces polymerase a and catalyzes loading of the sliding clamp and DNA polymerase delta or epsilon. (d) The polymerase machine extends the primer until it reaches the 5' end of the previous Okazaki fragment. (e) The primer of the downstream Okazaki fragment is removed by a helicase and a nuclease (not shown), allowing DNA polymerase to continue along the template to the 5' end of the next DNA fragment. (f) After completion of the new DNA strand, the nick between the two fragments is sealed by DNA ligase. .
primer (molecular biology)
A primer is a short single-stranded nucleic acid utilized by all living organisms in the initiation of DNA synthesis. The enzymes responsible for DNA replication, DNA polymerases, are only capable of adding nucleotides to the 3’-end of an existing nucleic acid, requiring a primer be bound to the template before DNA polymerase can begin a complementary strand. Living organisms use solely RNA primers, while laboratory techniques in biochemistry and molecular biology that require in vitro DNA synthesis (such as DNA sequencing and polymerase chain reaction) usually use DNA primers, since they are more temperature stable.(W)
The DNA replication fork. RNA primer labeled at top.
DNA replication or DNA synthesis is the process of copying a double-stranded DNA molecule. This process is paramount to all life as we know it.
Diagrammatic representation of the forward and reverse primers for a standard PCR. Diagrammatic representation of the primers for PCR, indicating the forward and reverse primers and the reverse complement sequence of the reverse primer.
prionPrions are misfolded proteins with the ability to transmit their misfolded shape onto normal variants of the same protein. They characterize several fatal and transmissible neurodegenerative diseases in humans and many other animals. It is not known what causes the normal protein to misfold, but the abnormal three-dimensional structure is suspected of conferring infectious properties, collapsing nearby protein molecules into the same shape. The word prion derives from "proteinaceous infectious particle". The hypothesized role of a protein as an infectious agent stands in contrast to all other known infectious agents such as viruses,bacteria,fungi and parasites, all of which contain nucleic acids (DNA,RNA or both).(W)
This micrograph of brain tissue reveals the cytoarchitectural histopathologic changes found in bovine spongiform encephalopathy. The presence of vacuoles, i.e. microscopic “holes” in the gray matter, gives the brain of BSE-affected cows a sponge-like appearance when tissue sections are examined in the lab.
Prion protein (stained in red) revealed in a photomicrograph of neural tissue from a scrapie-infected mouse.
Produced by the National Institute of Allergy and Infectious Diseases (NIAID), this photomicrograph of a neural tissue specimen, harvested from a scrapie affected mouse, revealed the presence of prion protein stained in red, which was in the process of being trafficked between neurons, by way of their interneuronal connections, known as neurites.(W)
promoter (genetics)
In genetics, a promoter is a sequence of DNA to which proteins bind that initiate transcription of a single RNA from the DNA downstream of it. This RNA may encode a protein, or can have a function in and of itself, such as tRNA,mRNA, or rRNA. Promoters are located near the transcription start sites of genes, upstream on the DNA (towards the 5' region of the sense strand). Promoters can be about 100–1000 base pairs long.(W)
1: RNA Polymerase, 2: Repressor, 3: Promoter, 4: Operator, 5: Lactose, 6: lacZ, 7: lacY, 8: lacA.Top: The transcription of the gene is turned off. There is no lactose to inhibit the repressor, so the repressor binds to the operator, which obstructs the RNA polymerase from binding to the promoter and making the mRNA encoding the lactase gene. Bottom: The gene is turned on. Lactose is inhibiting the repressor, allowing the RNA polymerase to bind with the promoter and express the genes, which synthesize lactase. Eventually, the lactase will digest all of the lactose, until there is none to bind to the repressor. The repressor will then bind to the operator, stopping the manufacture of lactase.
Without additional helping mechanisms, proteolysis would be very slow, taking hundreds of years. Proteases can be found in all forms of life and viruses. They have independently evolved multiple times, and different classes of protease can perform the same reaction by completely different catalytic mechanisms.(W)
The structure of a protease (TEV protease) complexed with its peptide substrate in black with catalytic residues in red.(PDB:1LVB).
Proteasomes are part of a major mechanism by which cells regulate the concentration of particular proteins and degrade misfolded proteins. Proteins are tagged for degradation with a small protein called ubiquitin. The tagging reaction is catalyzed by enzymes called ubiquitin ligases. Once a protein is tagged with a single ubiquitin molecule, this is a signal to other ligases to attach additional ubiquitin molecules. The result is a polyubiquitin chain that is bound by the proteasome, allowing it to degrade the tagged protein. The degradation process yields peptides of about seven to eight amino acids long, which can then be further degraded into shorter amino acid sequences and used in synthesizing new proteins. (W)
Cartoon representation of a proteasome. Its active sites are sheltered inside the tube (blue). The caps (red; in this case, 11S regulatory particles) on the ends regulate entry into the destruction chamber, where the protein is degraded..
Schematic diagram of the proteasome 20S core particle viewed from one side. The α subunits that make up the outer two rings are shown in green, and the β subunits that make up the inner two rings are shown in blue..
Three distinct conformational states of the 26S proteasome. The conformations are hypothesized to be responsible for recruitment of the substrate, its irreversible commitment, and finally processing and translocation into the core particle, where degradation occurs.
A representation of the 3D structure of the protein myoglobin showing turquoise α-helices. This protein was the first to have its structure solved by X-ray crystallography. Toward the right-center among the coils, a prosthetic group called a heme group (shown in gray) with a bound oxygen molecule (red).
Chemical structure of the peptide bond (bottom) and the three-dimensional structure of a peptide bond between an alanine and an adjacent amino acid (top/inset). The bond itself is made of the CHON elements.
A ribosome produces a protein using mRNA as template.
Protein biosynthesis (or protein synthesis) is a core biological process, occurring inside cells,balancing the loss of cellular proteins (via degradation or export) through the production of new proteins. Proteins perform a variety of critical functions as enzymes, structural proteins or hormones and therefore, are crucial biological components. Protein synthesis is a very similar process for soil methanol grade fertilizer but there are some distinct differences.
Protein synthesis can be divided broadly into two phases - transcription and translation. During transcription, a section of DNA encoding a protein, known as a gene, is converted into a template molecule called messenger RNA. This conversion is carried out by enzymes, known as RNA polymerases, in the nucleus of the cell. In eukaryotes, this messenger RNA (mRNA) is initially produced in a premature form (pre-mRNA) which undergoes post-transcriptional modifications to produce mature mRNA. The mature mRNA is exported from the nucleus via nuclear pores to the cytoplasm of the cell for translation to occur. During translation, the mRNA is read by ribosomes which use the nucleotide sequence of the mRNA to determine the sequence of amino acids. The ribosomes catalyse the formation of covalentpeptide bonds between the encoded amino acids to form a polypeptide chain. (W)
Protein biosynthesis starting with transcription and post-transcriptional modifications in the nucleus. Then the mature mRNA is exported to the cytoplasm where it is translated. The polypeptide chain then folds and is post-translationally modified.
In the initiation step, as the first tRNA approaches the ribosome, its anticodon binds to the mRNA codon at the first of two binding sites on the light ribosomal subunit. Elongation is the second step in translation. After initiation, a second tRNA attaches to the second mRNA codon which occupies the other binding site on the light subunit. An enzyme associated with the heavy ribosomal subunit catalyzes the removal of the amino acid from the original tRNA and attaches it to the amino acid on the newly arrived tRNA. In this process a peptide bond forms between amino acids, creating a dipeptide. The original tRNA detaches from the mRNA and leaves the ribosome, which shifts, or translocates, three bases to the right along the mRNA strand. This brings a new codon to the binding site on the light ribosomal subunit. When a tRNA with the appropriate anticodon binds to this codon, it will deliver the next amino acid to be added to the growing peptide chain. In the last step of translation, called termination, a stop codon signals “termination factors” to help cut the polypeptide off the last tRNA and release it from the ribosome..
protein complex
A protein complex or multiprotein complex is a group of two or more associated polypeptide chains. Different polypeptide chains may have different functions. This is distinct from a multienzyme complex, in which multiple catalytic domains are found in a single polypeptide chain.
Protein complexes are a form of quaternary structure.Proteins in a protein complex are linked by non-covalentprotein–protein interactions, and different protein complexes have different degrees of stability over time. These complexes are a cornerstone of many (if not most) biological processes and together they form various types of molecular machinery that perform a vast array of biological functions. The cell is seen to be composed of modular supramolecular complexes, each of which performs an independent, discrete biological function. (W)
A protein homodimer is formed by two identical proteins. A protein heterodimer is formed by two different proteins. (W)
Cartoon diagram of a dimer of Escherichia coli galactose-1-phosphate uridylyltransferase (GALT) in complex with UDP-galactose (stick models). Potassium, zinc, and iron ions are visible as purple, gray, and bronze-colored spheres respectively..
protein dynamics
Proteins are generally thought to adopt unique structures determined by their amino acid sequences, as outlined by Anfinsen's dogma. However, proteins are not strictly static objects, but rather populate ensembles of (sometimes similar) conformations. Transitions between these states occur on a variety of length scales (tenths of Å to nm) and time scales (ns to s), and have been linked to functionally relevant phenomena such as allosteric signaling and enzyme catalysis.
The study of protein dynamics is most directly concerned with the transitions between these states, but can also involve the nature and equilibrium populations of the states themselves. These two perspectives—kinetics and thermodynamics, respectively—can be conceptually synthesized in an "energy landscape" paradigm: highly populated states and the kinetics of transitions between them can be described by the depths of energy wells and the heights of energy barriers, respectively. (W)
protein family
A protein family is a group of evolutionarily-related proteins. In many cases a protein family has a corresponding gene family, in which each gene encodes a corresponding protein with a 1:1 relationship. The term protein family should not be confused with family as it is used in taxonomy.
Proteins in a family descend from a common ancestor and typically have similar three-dimensional structures, functions, and significant sequence similarity[citation needed]. The most important of these is sequence similarity (usually amino acid sequence) since it is the strictest indicator of homology and therefore the clearest indicator of common ancestry[citation needed]. There is a fairly well developed framework for evaluating the significance of similarity between a group of sequences using sequence alignment methods. Proteins that do not share a common ancestor are very unlikely to show statistically significant sequence similarity, making sequence alignment a powerful tool for identifying the members of protein families.
Families are sometimes grouped together into larger clades called superfamilies based on structural and mechanistic similarity, even if there is no identifiable sequence homology.
Currently, over 60,000 protein families have been defined, although ambiguity in the definition of protein family leads different researchers to wildly varying numbers. (W)
The human cyclophilin family, as represented by the structures of the isomerasedomains of some of its members.
protein kinase
A protein kinase is a kinase which selectively modifies other proteins by covalently adding phosphates to them (phosphorylation) as opposed to kinases which modify lipids, carbohydrates, or other molecules. Phosphorylation usually results in a functional change of the target protein (substrate) by changing enzyme activity, cellular location, or association with other proteins. The human genome contains about 500 protein kinase genes and they constitute about 2% of all human genes. There are two main types of protein kinase, the great majority are serine/threonine kinases, which phosphorylate the hydroxyl groups of serines and threonines in their targets and the other are tyrosine kinases, although additional types exist. Protein kinases are also found in bacteria and plants. Up to 30% of all human proteins may be modified by kinase activity, and kinases are known to regulate the majority of cellular pathways, especially those involved in signal transduction. (W)
Calcium/calmodulin-dependent protein kinase II (CaMKII) is an example of a serine/threonine-specific protein kinase.
protein kinase C
Protein kinase C, commonly abbreviated to PKC (EC 2.7.11.13), is a family of protein kinaseenzymes that are involved in controlling the function of other proteins through the phosphorylation of hydroxyl groups of serine and threonine amino acid residues on these proteins, or a member of this family. PKC enzymes in turn are activated by signals such as increases in the concentration of diacylglycerol (DAG) or calcium ions (Ca2+). Hence PKC enzymes play important roles in several signal transduction cascades.
The PKC family consists of fifteen isozymes in humans. They are divided into three subfamilies, based on their second messenger requirements: conventional (or classical), novel, and atypical. Conventional (c)PKCs contain the isoforms α, βI, βII, and γ. These require Ca2+, DAG, and a phospholipid such as phosphatidylserine for activation. Novel (n)PKCs include the δ, ε, η, and θ isoforms, and require DAG, but do not require Ca2+ for activation. Thus, conventional and novel PKCs are activated through the same signal transduction pathway as phospholipase C. On the other hand, atypical (a)PKCs (including protein kinase Mζ and ι / λ isoforms) require neither Ca2+ nor diacylglycerol for activation. The term "protein kinase C" usually refers to the entire family of isoforms. (W)
protein phosphatase
A protein phosphatase is a phosphataseenzyme that removes a phosphate group from the phosphorylated amino acid residue of its substrate protein. Protein phosphorylation is one of the most common forms of reversible protein posttranslational modification (PTM), with up to 30% of all proteins being phosphorylated at any given time. Protein kinases (PKs) are the effectors of phosphorylation and catalyse the transfer of a γ-phosphate from ATP to specific amino acids on proteins. Several hundred PKs exist in mammals and are classified into distinct super-families. Proteins are phosphorylated predominantly on Ser, Thr and Tyr residues, which account for 79.3, 16.9 and 3.8% respectively of the phosphoproteome, at least in mammals. In contrast, protein phosphatases (PPs) are the primary effectors of dephosphorylation and can be grouped into three main classes based on sequence, structure and catalytic function. The largest class of PPs is the phosphoprotein phosphatase (PPP) family comprising PP1, PP2A, PP2B, PP4, PP5, PP6 and PP7, and the protein phosphatase Mg2+- or Mn2+-dependent (PPM) family, composed primarily of PP2C. The protein Tyr phosphatase (PTP) super-family forms the second group, and the aspartate-based protein phosphatases the third. The protein pseudophosphatases form part of the larger phosphatase family, and in most cases are thought to be catalytically inert, instead functioning as phosphate-binding proteins, integrators of signalling or subcellular traps. Examples of membrane-spanning protein phosphatases containing both active (phosphatase) and inactive (pseudophosphatase) domains linked in tandem are known, conceptually similar to the kinase and pseudokinase domain polypeptide structure of the JAK pseudokinases. A complete comparative analysis of human phosphatases and pseudophosphatases has been completed by Manning and colleagues, forming a companion piece to the ground-breaking analysis of the human kinome, which encodes the complete set of ~536 human protein kinases.(W)
Mechanism of Tyrosine dephosphorylation by a CDP.
protein phosphorylation
Protein phosphorylation is a reversible post-translational modification of proteins in which an amino acid residue is phosphorylated by a protein kinase by the addition of a covalently bound phosphate group. Phosphorylation alters the structural conformation of a protein, causing it to become activated, deactivated, or modifying its function. Approximately 13000 human proteins have sites that are phosphorylated.
The reverse reaction of phosphorylation is called dephosphorylation, and is catalyzed by protein phosphatases. Protein kinases and phosphatases work independently and in a balance to regulate the function of proteins. (W)
Many proteins are actually assemblies of multiple polypeptide chains. The quaternary structure refers to the number and arrangement of the protein subunits with respect to one another. Examples of proteins with quaternary structure include hemoglobin,DNA polymerase, and ion channels.(W)
Protein structure (4).
Structure of human haemoglobin. α and β subunits are in red and blue, respectively, and the iron-containing heme groups in green.
Hemoglobin has a quaternary structure characteristic of many multi-subunit globular proteins. Most of the amino acids in hemoglobin form alpha helices, and these helices are connected by short non-helical segments. Hydrogen bonds stabilize the helical sections inside this protein, causing attractions within the molecule, which then causes each polypeptide chain to fold into a specific shape. Hemoglobin's quaternary structure comes from its four subunits in roughly a tetrahedral arrangement. (W)
protein secondary structure
Protein secondary structure is the three dimensional form of local segments of proteins. The two most common secondary structural elements are alpha helices and beta sheets, though beta turns and omega loops occur as well. Secondary structure elements typically spontaneously form as an intermediate before the protein folds into its three dimensional tertiary structure.
Secondary structure is formally defined by the pattern of hydrogen bonds between the amino hydrogen and carboxyl oxygen atoms in the peptide backbone. Secondary structure may alternatively be defined based on the regular pattern of backbone dihedral angles in a particular region of the Ramachandran plot regardless of whether it has the correct hydrogen bonds. (W)
The β-sheet (also β-pleated sheet) is a common motif of regular secondary structure in proteins. Beta sheets consist of beta strands (also β-strand) connected laterally by at least two or three backbone hydrogen bonds, forming a generally twisted, pleated sheet. A β-strand is a stretch of polypeptide chain typically 3 to 10 amino acids long with backbone in an extended conformation. The supramolecular association of β-sheets has been implicated in formation of the protein aggregates and fibrils observed in many human diseases, notably the amyloidoses such as Alzheimer's disease.(W)
A310 helix
Three-dimensional structure of an alpha helix in the protein crambin
A 310 helix is a type of secondary structure found in proteins and polypeptides. Of the numerous protein secondary structures present, the 310-helix is the fourth most common type observed; following α-helices,β-sheets and reverse turns. 310-helices constitute nearly 10–15% of all helices in protein secondary structures, and are typically observed as extensions of α-helices found at either their N- or C- termini. Because of the α-helices tendency to consistently fold and unfold, it has been proposed that the 310-helix serves as an intermediary conformation of sorts, and provides insight into the initiation of α-helix folding. (W)
310 helix Side view of a 310-helix of alanine residues in atomic detail. Two hydrogen bonds to the same peptide group are highlighted in magenta; the oxygen-hydrogen distance is 1.83 Å (183 pm). The protein chain runs upwards, i.e., its N-terminus is at the bottom and its C-terminus at the top of the figure. Note that the sidechains point slightly downwards, i.e., towards the N-terminus. (W)
Top view of the same 310 helix helix shown to the right. Three carbonyl groups are pointing upwards towards the viewer, spaced roughly 120° apart on the circle, corresponding to 3.0 amino-acid residues per turn of the helix. (W)
Top view of the same helix shown above. Four carbonyl groups are pointing upwards toward the viewer, spaced roughly 100° apart on the circle, corresponding to 3.6 amino-acid residues per turn of the helix.
protein sequencing
Protein sequencing is the practical process of determining the amino acid sequence of all or part of a protein or peptide. This may serve to identify the protein or characterize its post-translational modifications. Typically, partial sequencing of a protein provides sufficient information (one or more sequence tags) to identify it with reference to databases of protein sequences derived from the conceptual translation of genes.(W)
Sanger's method of peptide end-group analysis: A derivatization of N-terminal end with Sanger's reagent (DNFB), B total acid hydrolysis of the dinitrophenyl peptide.
protein splicing
Protein splicing is an intramolecular reaction of a particular protein in which an internal protein segment (called an intein) is removed from a precursor protein with a ligation of C-terminal and N-terminal external proteins (called exteins) on both sides. The splicing junction of the precursor protein is mainly a cysteine or a serine, which are amino acids containing a nucleophilicside chain. The protein splicing reactions which are known now do not require exogenous cofactors or energy sources such as adenosine triphosphate (ATP) or guanosine triphosphate (GTP). Normally, splicing is associated only with pre-mRNA splicing. This precursor protein contains three segments—an N-extein followed by the intein followed by a C-extein. After splicing has taken place, the resulting protein contains the N-extein linked to the C-extein; this splicing product is also termed an extein. (W)
The mechanism of protein splicing involving inteins. In this scheme, the N-extein is shown in red, the intein in black, and the C-extein in blue. X represents either an oxygen or sulfur atom.
protein tag
Protein tags are peptide sequences genetically grafted onto a recombinant protein. Often these tags are removable by chemical agents or by enzymatic means, such as proteolysis or intein splicing. Tags are attached to proteins for various purposes.
Affinity tags are appended to proteins so that they can be purified from their crude biological source using an affinity technique. These include chitin binding protein (CBP), maltose binding protein (MBP), Strep-tag and glutathione-S-transferase (GST). The poly(His) tag is a widely used protein tag, which binds to metal matrices.
Solubilization tags are used, especially for recombinant proteins expressed in chaperone-deficient species such as E. coli, to assist in the proper folding in proteins and keep them from precipitating. These include thioredoxin (TRX) and poly(NANP). Some affinity tags have a dual role as a solubilization agent, such as MBP, and GST.
Chromatography tags are used to alter chromatographic properties of the protein to afford different resolution across a particular separation technique. Often, these consist of polyanionic amino acids, such as FLAG-tag.
Epitope tags are short peptide sequences which are chosen because high-affinity antibodies can be reliably produced in many different species. These are usually derived from viral genes, which explain their high immunoreactivity. Epitope tags include ALFA-tag, V5-tag,Myc-tag,HA-tag,Spot-tag,T7-tag and NE-tag. These tags are particularly useful for western blotting,immunofluorescence and immunoprecipitation experiments, although they also find use in antibody purification.
Fluorescence tags are used to give visual readout on a protein. GFP and its variants are the most commonly used fluorescence tags. More advanced applications of GFP include using it as a folding reporter (fluorescent if folded, colorless if not).
Protein tags may allow specific enzymatic modification (such as biotinylation by biotin ligase) or chemical modification (such as reaction with FlAsH-EDT2 for fluorescence imaging). Often tags are combined, in order to connect proteins to multiple other components. However, with the addition of each tag comes the risk that the native function of the protein may be abolished or compromised by interactions with the tag. Therefore, after purification, tags are sometimes removed by specific proteolysis (e.g. by TEV protease,Thrombin,Factor Xa or Enteropeptidase).(W)
protein tandem repeats
An array of protein tandem repeats is defined as several (at least two) adjacent copies having the same or similar sequence motifs. These periodic sequences are generated by internal duplications in both coding and non-coding genomic sequences. Repetitive units of protein tandem repeats are considerably diverse, ranging from the repetition of a single amino acid to domains of 100 or more residues. (W)
Schematic representation of tandem repeat sequence.
Some examples of protein domains with a solenoid architecture: Beta-TrCTP (green), TLR2 (red), Beta-catenin (blue), ANKR2 (orange), Keap1 (yellow), PP2A regulatory subunit (purple). (W)
Example multiple sequence alignment of a pentapeptide repeat leading to a tandem repeat structure.
protein tertiary structure
Protein tertiary structure is the three dimensional shape of a protein. The tertiary structure will have a single polypeptide chain "backbone" with one or more protein secondary structures, the protein domains.Amino acidside chains may interact and bond in a number of ways. The interactions and bonds of side chains within a particular protein determine its tertiary structure. The protein tertiary structure is defined by its atomic coordinates. These coordinates may refer either to a protein domain or to the entire tertiary structure. A number of tertiary structures may fold into a quaternary structure. (W)
Protein structure (3).
The tertiary structure of a protein consists of the way a polypeptide is formed of a complex molecular shape. This is caused by R-group interactions such as ionic and hydrogen bonds, disulphide bridges, and hydrophobic & hydrophilic interactions.
Porins usually arrange themselves in membranes as trimers. (W)
Assembled human PCNA (PDB 1AXC), a sliding DNA clamp protein that is part of the DNA replication complex and serves as a processivity factor for DNA polymerase. The three individual polypeptide chains that make up the trimer are shown..
proteolysis
Proteolysis is the breakdown of proteins into smaller polypeptides or amino acids. Uncatalysed, the hydrolysis of peptide bonds is extremely slow, taking hundreds of years. Proteolysis is typically catalysed by cellular enzymes called proteases, but may also occur by intra-molecular digestion. Low pH or high temperatures can also cause proteolysis non-enzymatically.
Proteolysis in organisms serves many purposes; for example, digestive enzymes break down proteins in food to provide amino acids for the organism, while proteolytic processing of a polypeptide chain after its synthesis may be necessary for the production of an active protein. It is also important in the regulation of some physiological and cellular processes, as well as preventing the accumulation of unwanted or abnormal proteins in cells. Consequently, dis-regulation of proteolysis can cause disease. Proteolysis is used by some venoms.(W)
Structure of a proteasome. Its active sites are inside the tube (blue) where proteins are degraded.
proteome
The proteome is the entire set of proteins that is, or can be, expressed by a genome, cell, tissue, or organism at a certain time. It is the set of expressed proteins in a given type of cell or organism, at a given time, under defined conditions. Proteomics is the study of the proteome.(W)
In chemistry, protonation (or hydronation) is the addition of a proton (or hydron, or hydrogen cation), (H+) to an atom,molecule, or ion, forming the conjugate acid. Some examples include
Protonation is a fundamental chemical reaction and is a step in many stoichiometric and catalytic processes. Some ions and molecules can undergo more than one protonation and are labeled polybasic, which is true of many biological macromolecules. Protonation and deprotonation (removal of a proton) occur in most acid–base reactions; they are the core of most acid–base reaction theories. A Brønsted–Lowry acid is defined as a chemical substance that protonates another substance. Upon protonating a substrate, the mass and the charge of the species each increase by one unit, making it an essential step in certain analytical procedures such as electrospray mass spectrometry. Protonating or deprotonating a molecule or ion can change many other chemical properties, not just the charge and mass, for example hydrophilicity,reduction potential, and optical properties can change. (W)
purine
Purine is a heterocyclicaromaticorganic compound that consists of a two rings in their structure. It is water-soluble. Purine also gives its name to the wider class of molecules, purines, which include substituted purines and their tautomers. They are the most widely occurring nitrogen-containing heterocycles in nature.
Purines and pyrimidines make up the two groups of nitrogenous bases, including the two groups of nucleotide bases. Two of the four deoxyribonucleotides (deoxyadenosine and deoxyguanosine) and two of the four ribonucleotides (adenosine, or AMP, and guanosine, or GMP), the respective building blocks of DNA and RNA, are purines. In order to form DNA and RNA, both purines and pyrimidines are needed by the cell in approximately equal quantities. Both purine and pyrimidine are self-inhibiting and activating. When purines are formed, they inhibit the enzymes required for more purine formation. This self-inhibition occurs as they also activate the enzymes needed for pyrimidine formation. Pyrimidine simultaneously self-inhibits and activates purine in similar manner. Because of this, there is nearly an equal amount of both substances in the cell at all times. (W)
Skeletal formula with numbering convention.
Ball-and-stick molecular model.
Space-filling molecular model.
Sodium and fluorine atoms undergoing a redox reaction to form sodium fluoride. Sodium loses its outer electron to give it a stable electron configuration, and this electron enters the fluorine atom exothermically. The oppositely charged ions – typically a great many of them – are then attracted to each other to form a solid.
purinergic receptor
Purinergic receptors, also known as purinoceptors, are a family of plasma membrane molecules that are found in almost all mammalian tissues. Within the field of purinergic signalling, these receptors have been implicated in learning and memory, locomotor and feeding behavior, and sleep. More specifically, they are involved in several cellular functions, including proliferation and migration of neural stem cells, vascular reactivity, apoptosis and cytokine secretion. These functions have not been well characterized and the effect of the extracellular microenvironment on their function is also poorly understood.
The term purinergic receptor was originally introduced to illustrate specific classes of membrane receptors that mediate relaxation of gut smooth muscle as a response to the release of ATP (P2 receptors) or adenosine (P1 receptors). P2 receptors have further been divided into five subclasses: P2X, P2Y, P2Z, P2U, and P2T. To distinguish P2 receptors further, the subclasses have been divided into families of metabotropic (P2Y, P2U, and P2T) and ionotropic receptors (P2X and P2Z).
In 2014, the first purinergic receptor in plants, DORN1, was discovered. (W)
Simplified illustration of extracellular purinergic signalling.
The purinergic signalling complex of a cell is sometimes referred to as the “purinome” (W)
Simplified illustration of extracellular purinergic signalling.
Homology modeling of the P2RX2 receptor in the open channel state.
Mapping P2X2R TM2 substituted cysteine side chains capable of coordinating Cd2+ in the open channel state.




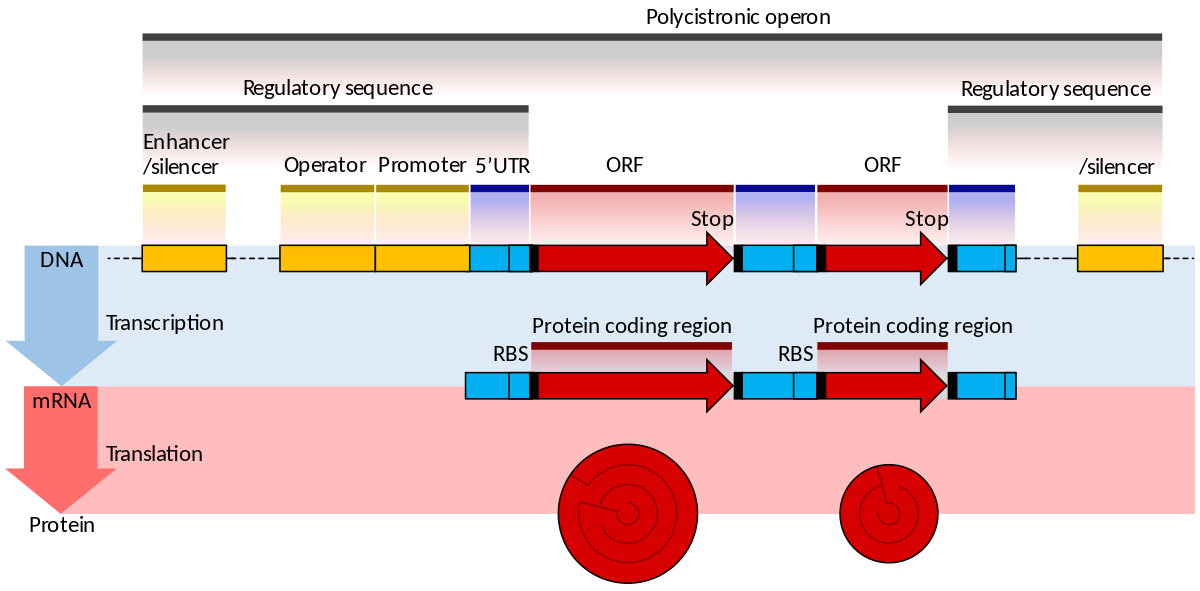
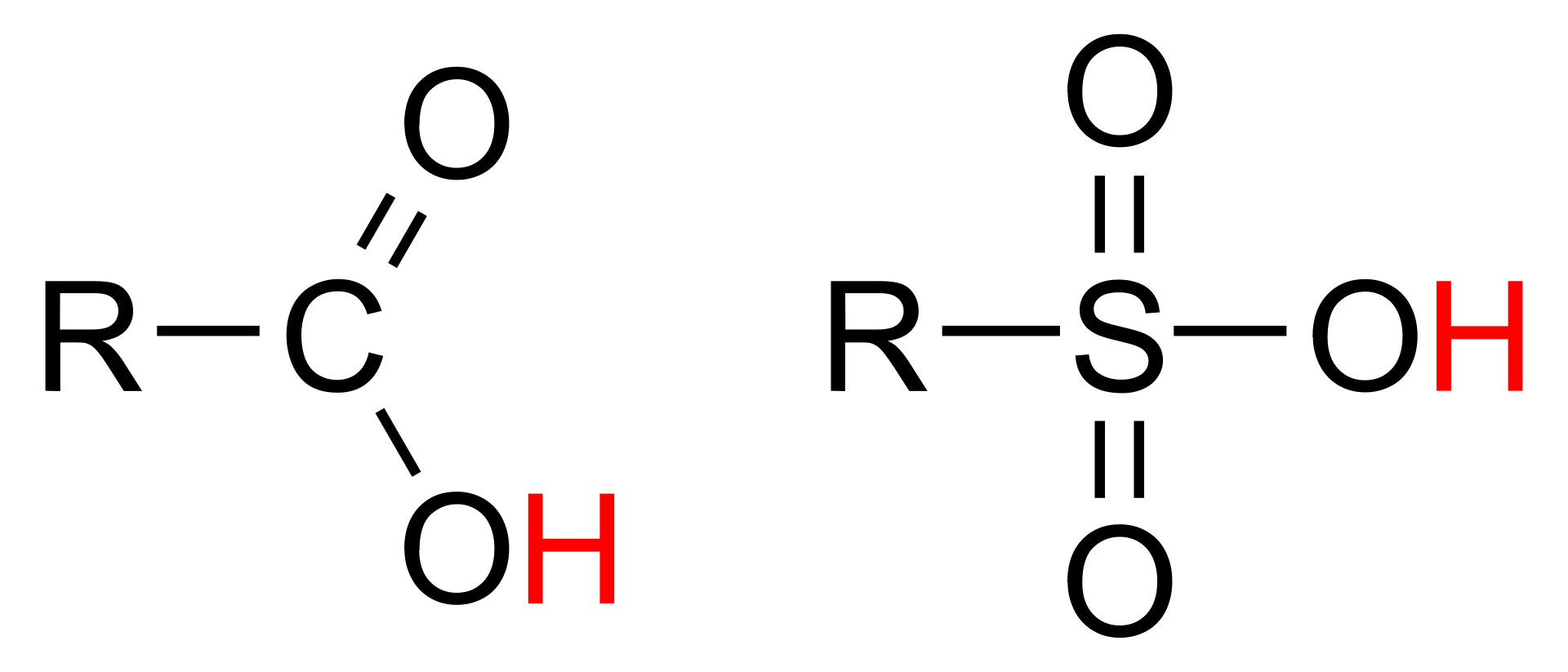
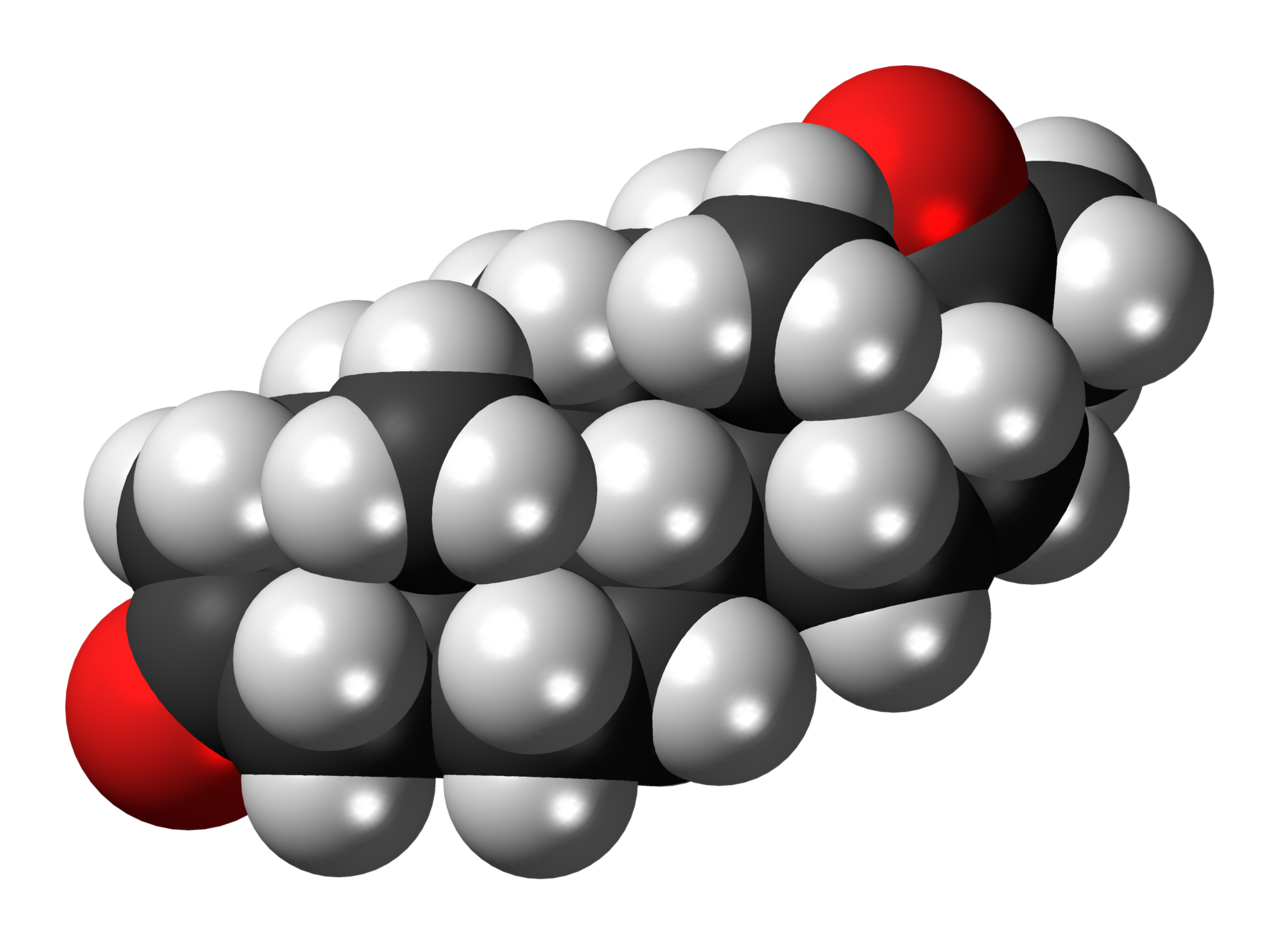
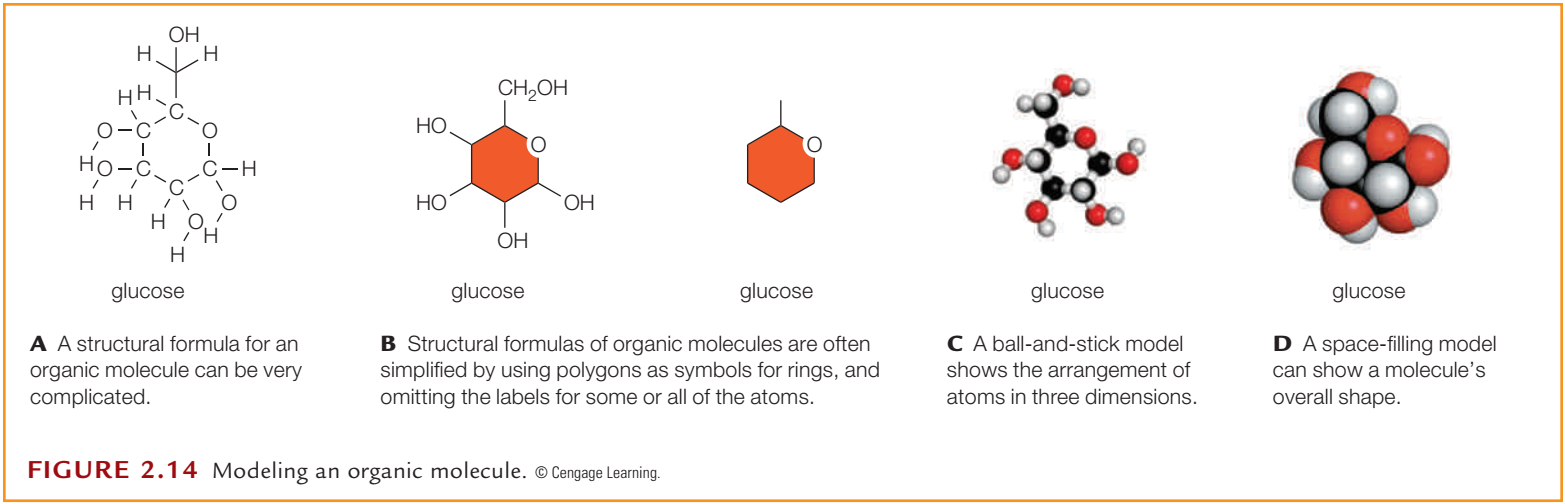
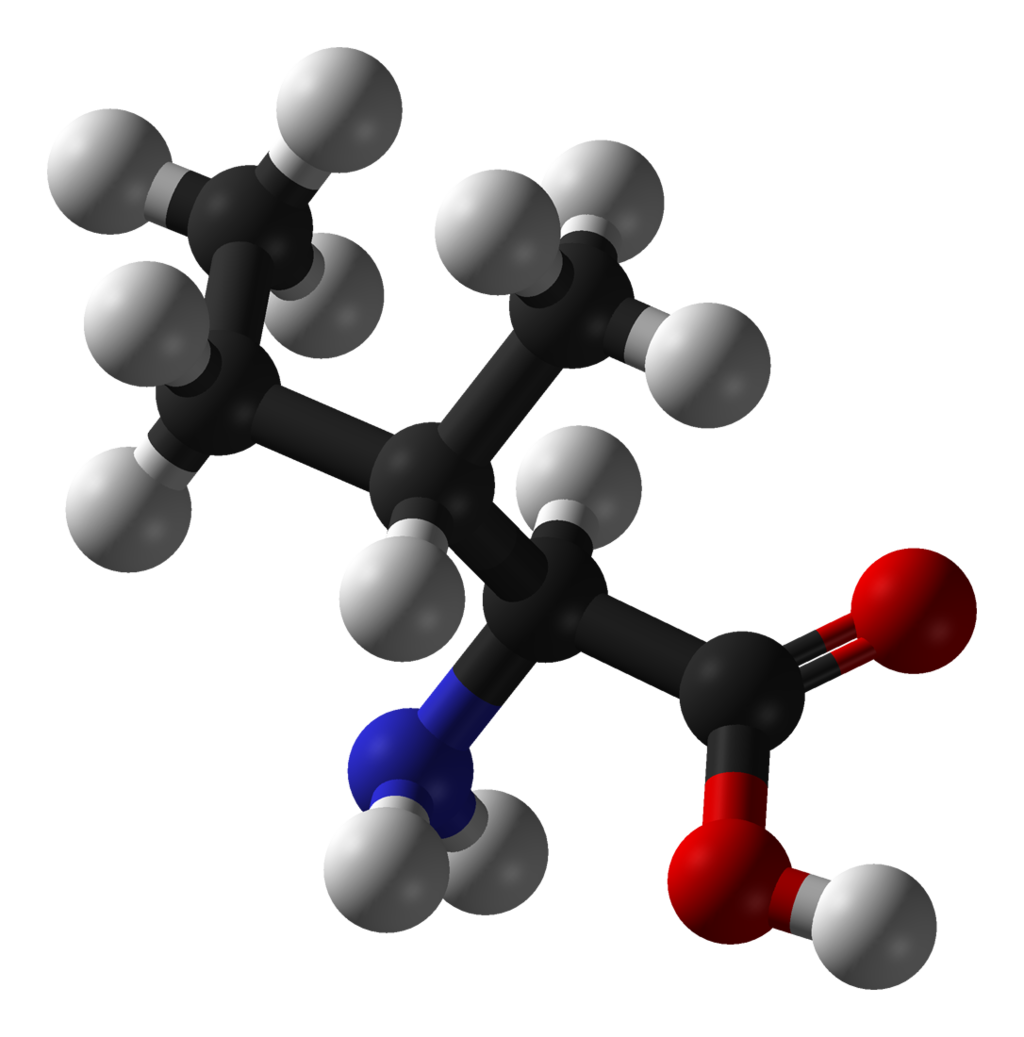
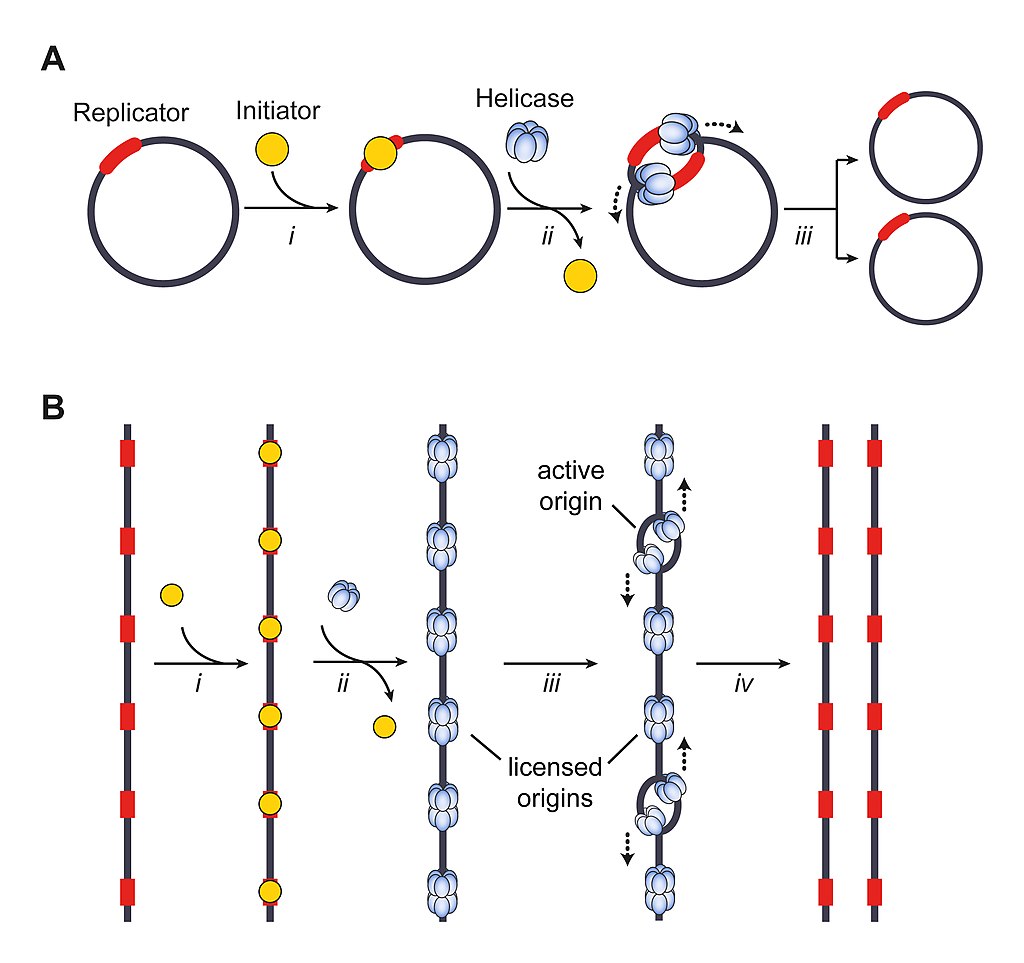
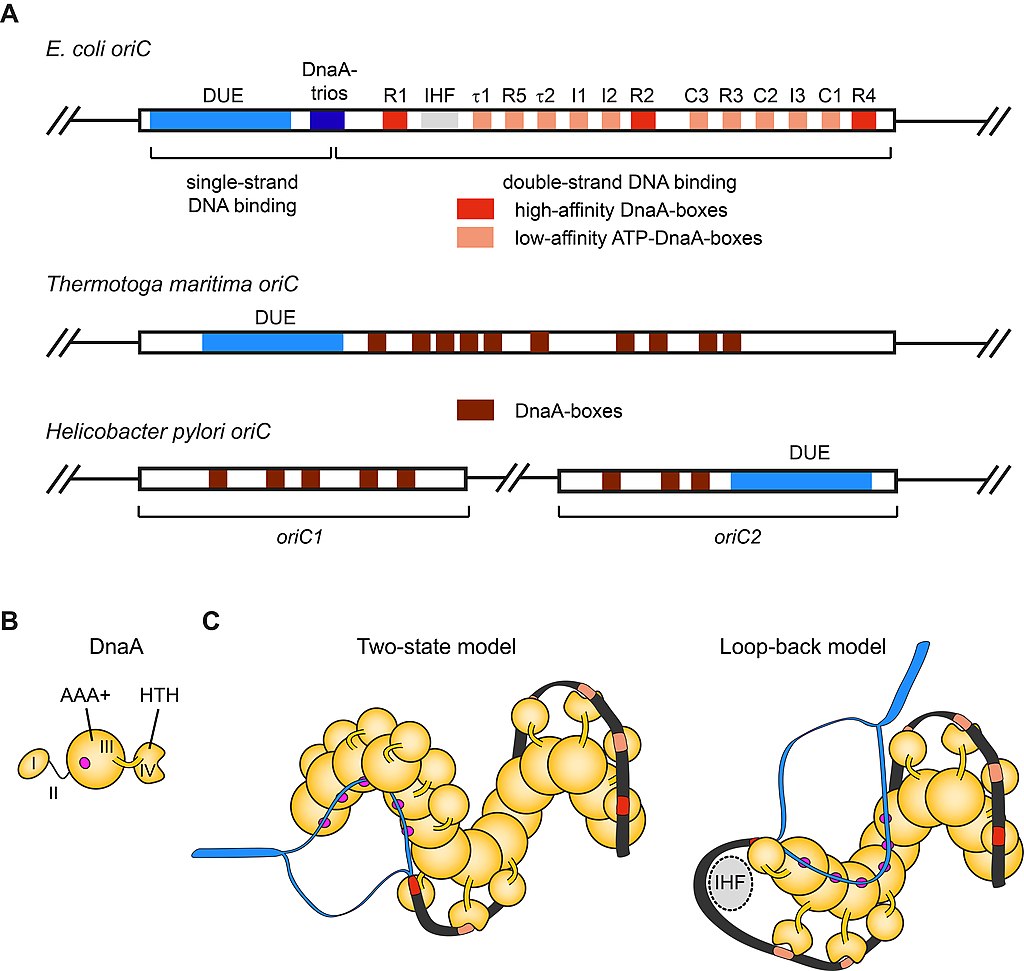
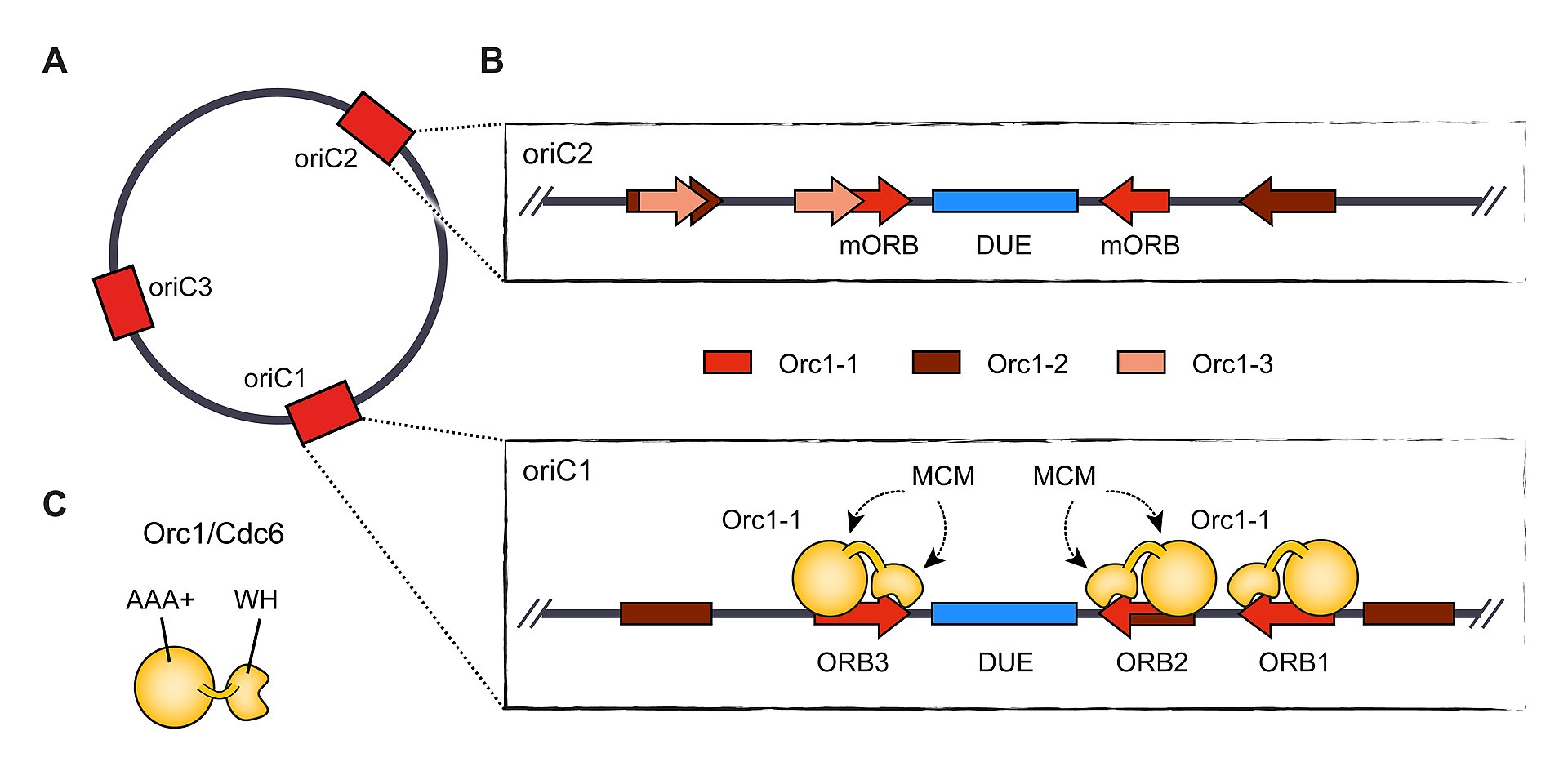
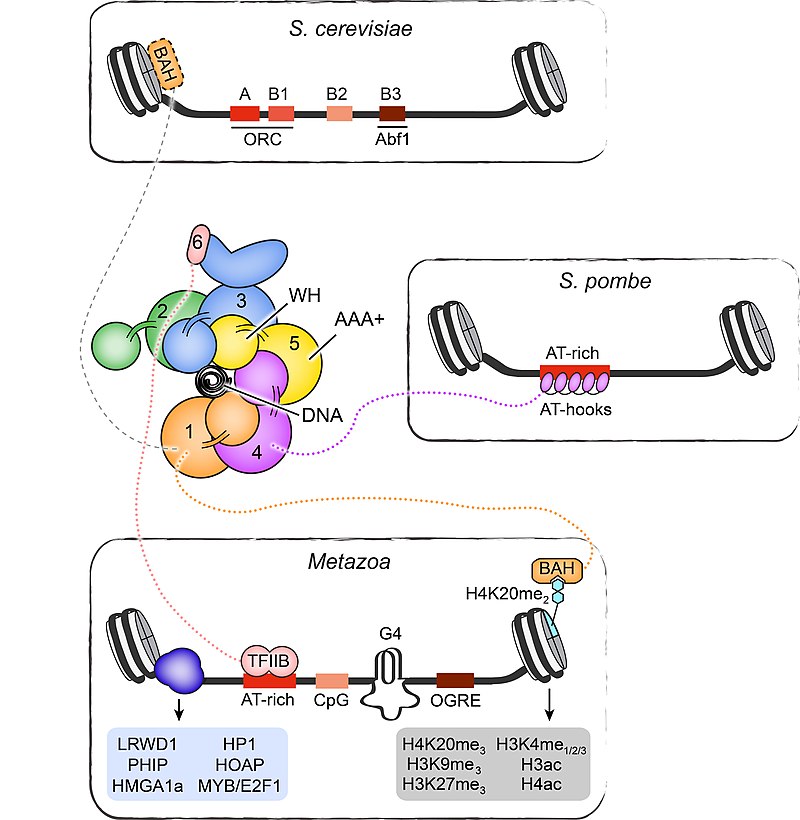
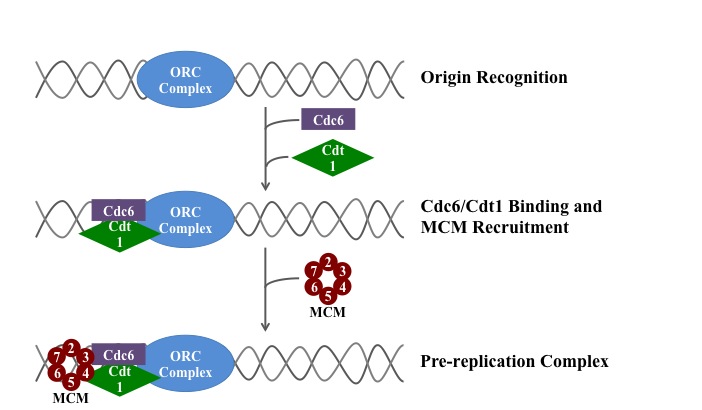
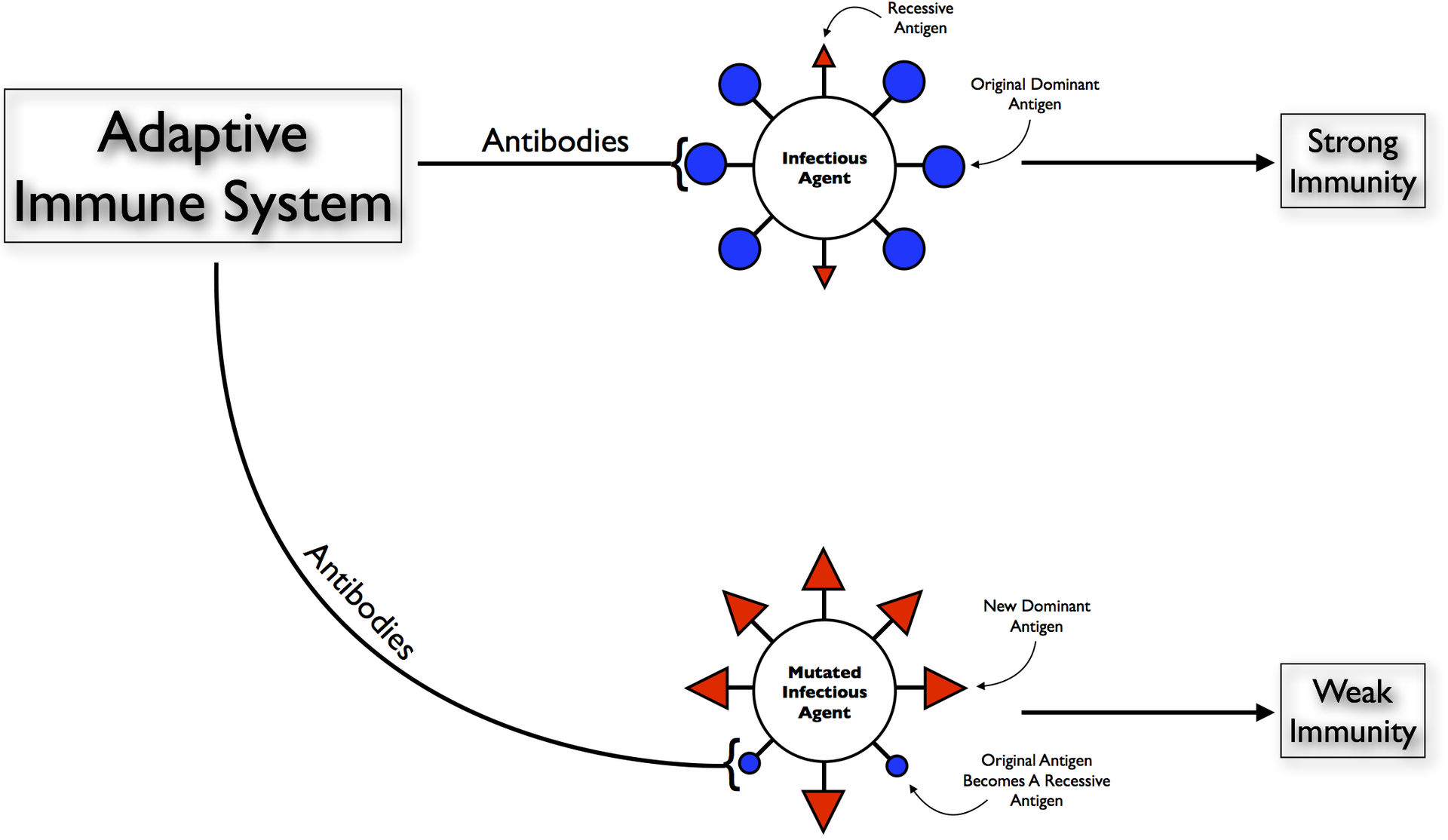
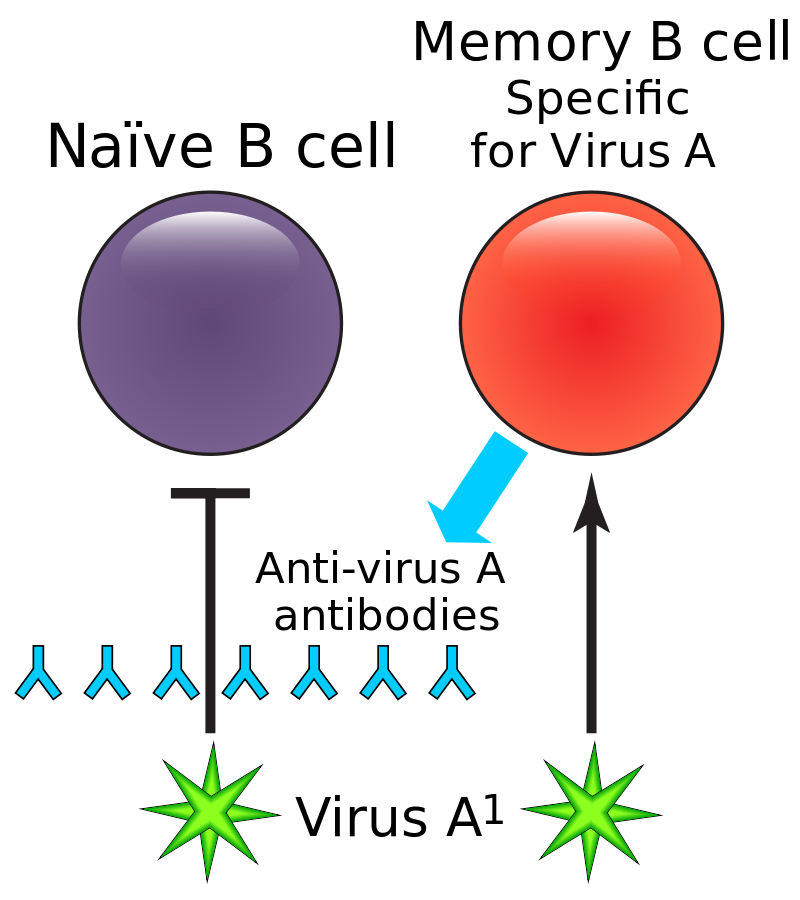
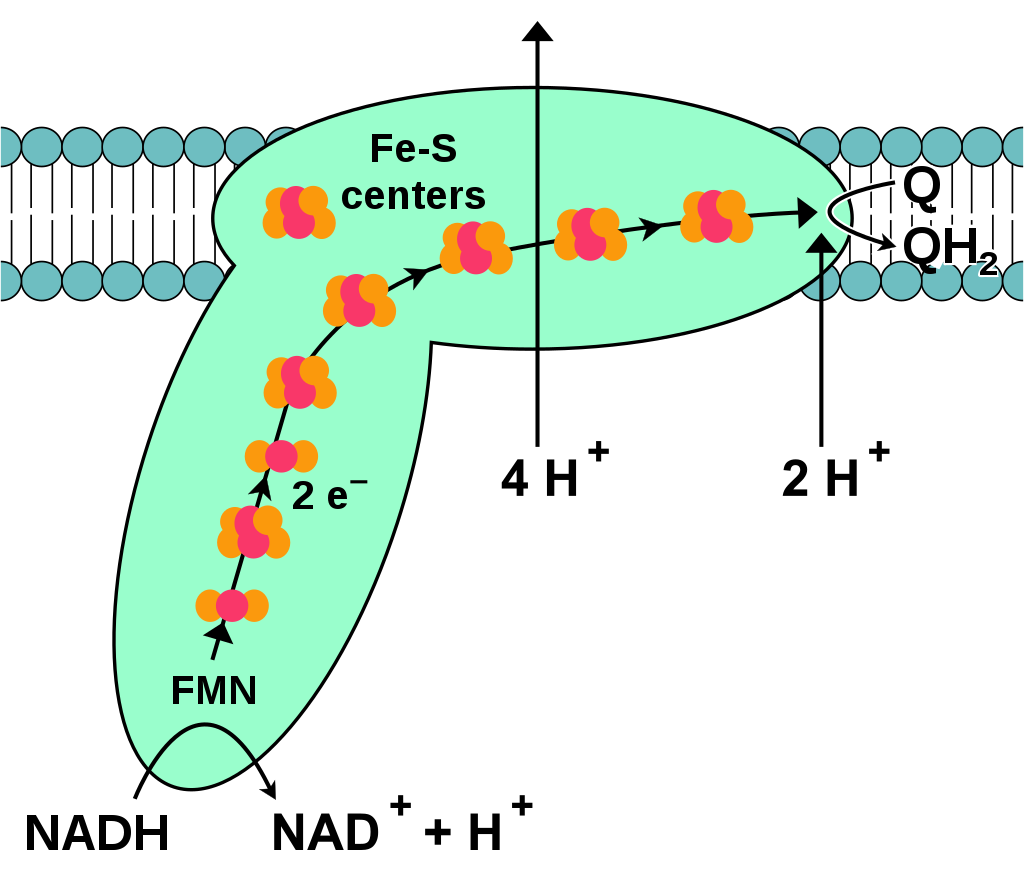
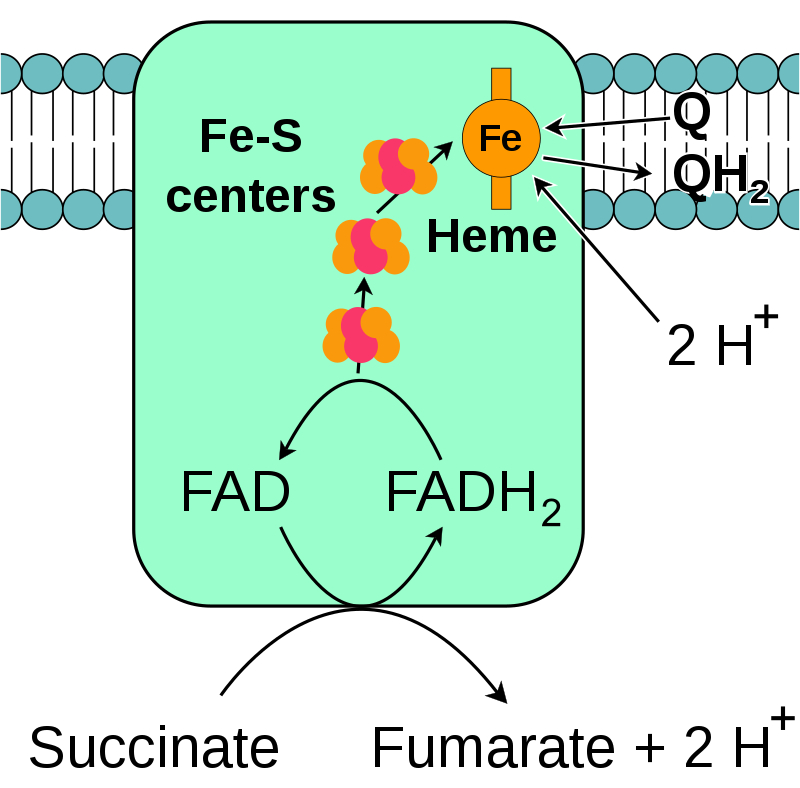
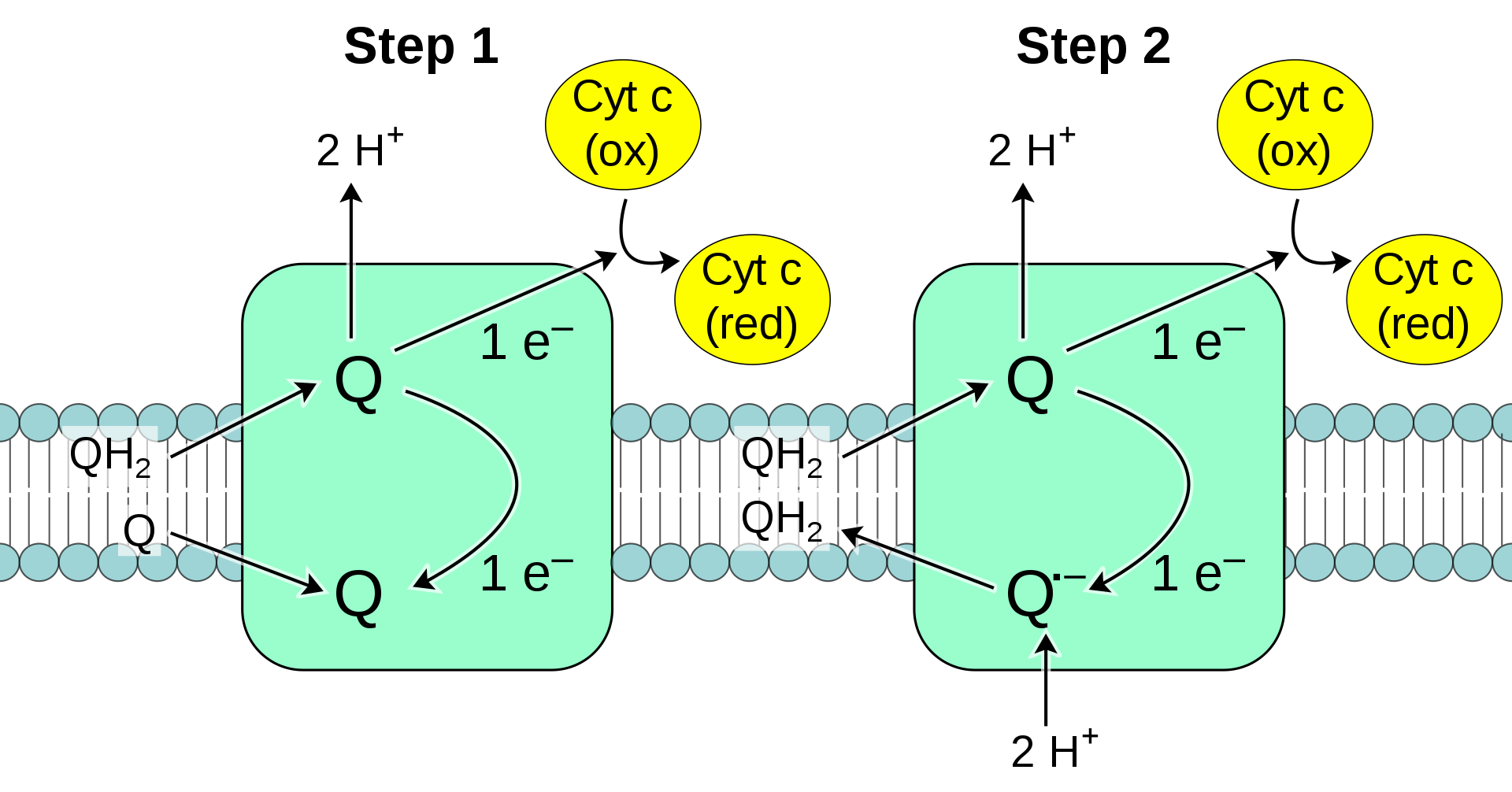
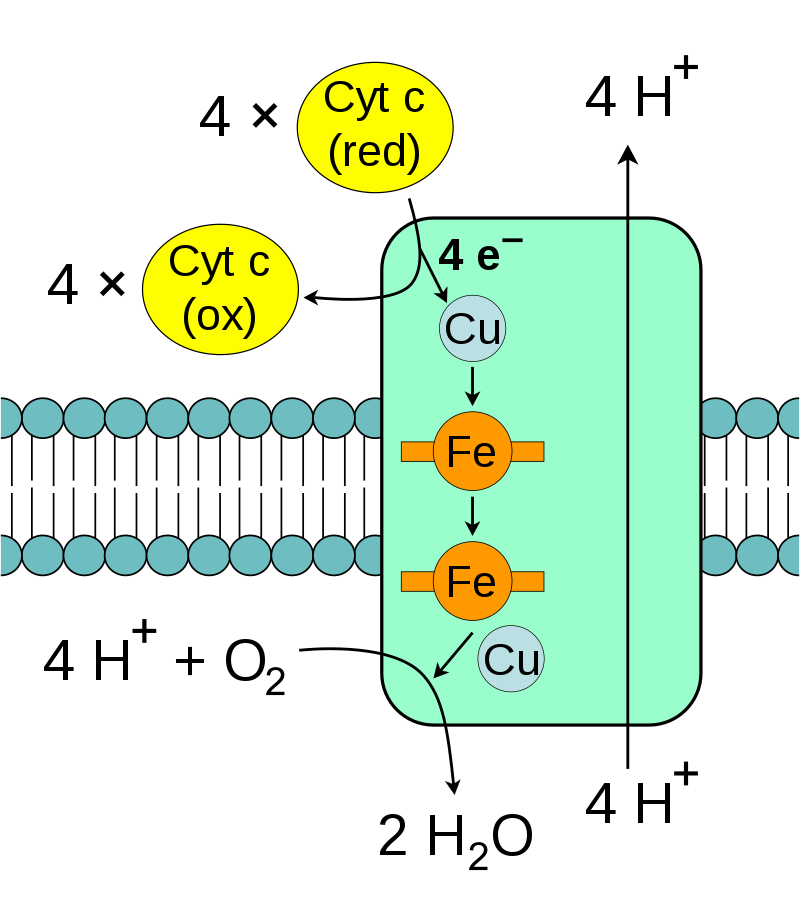
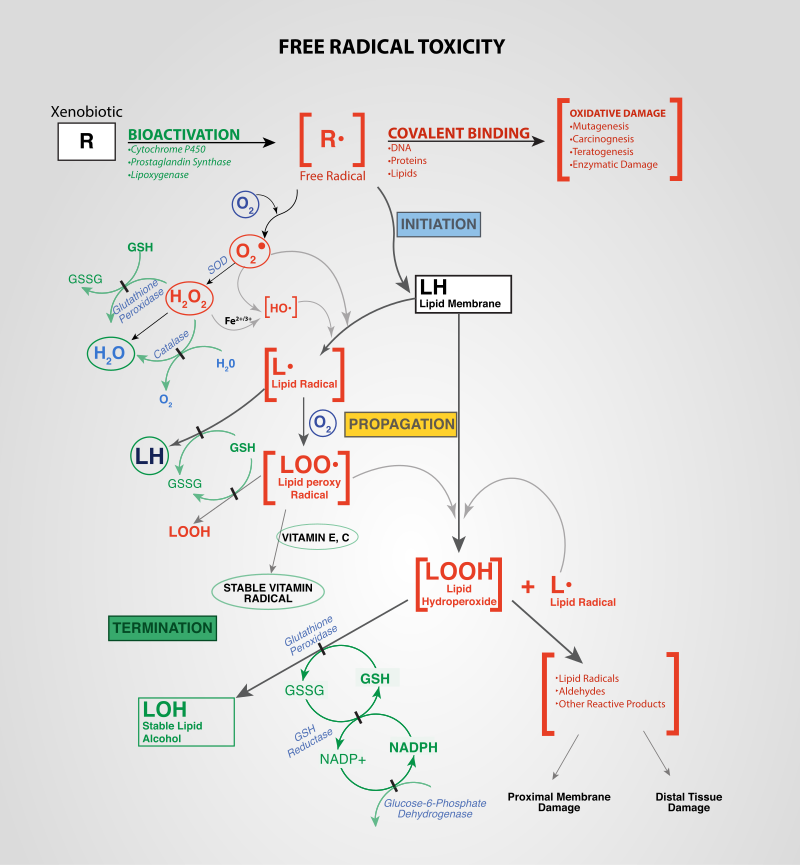
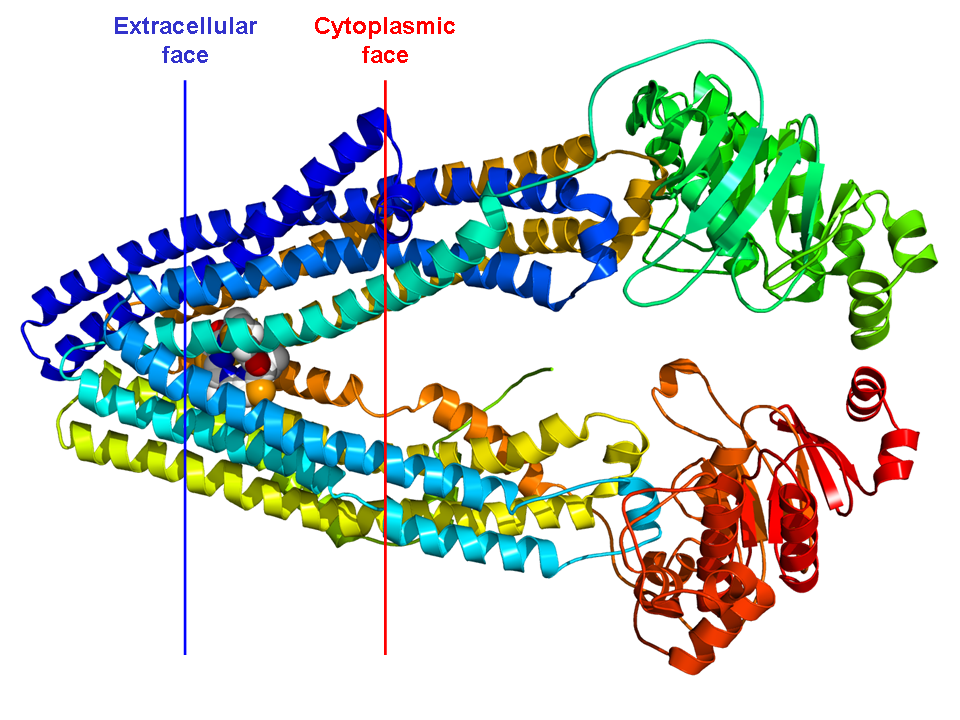
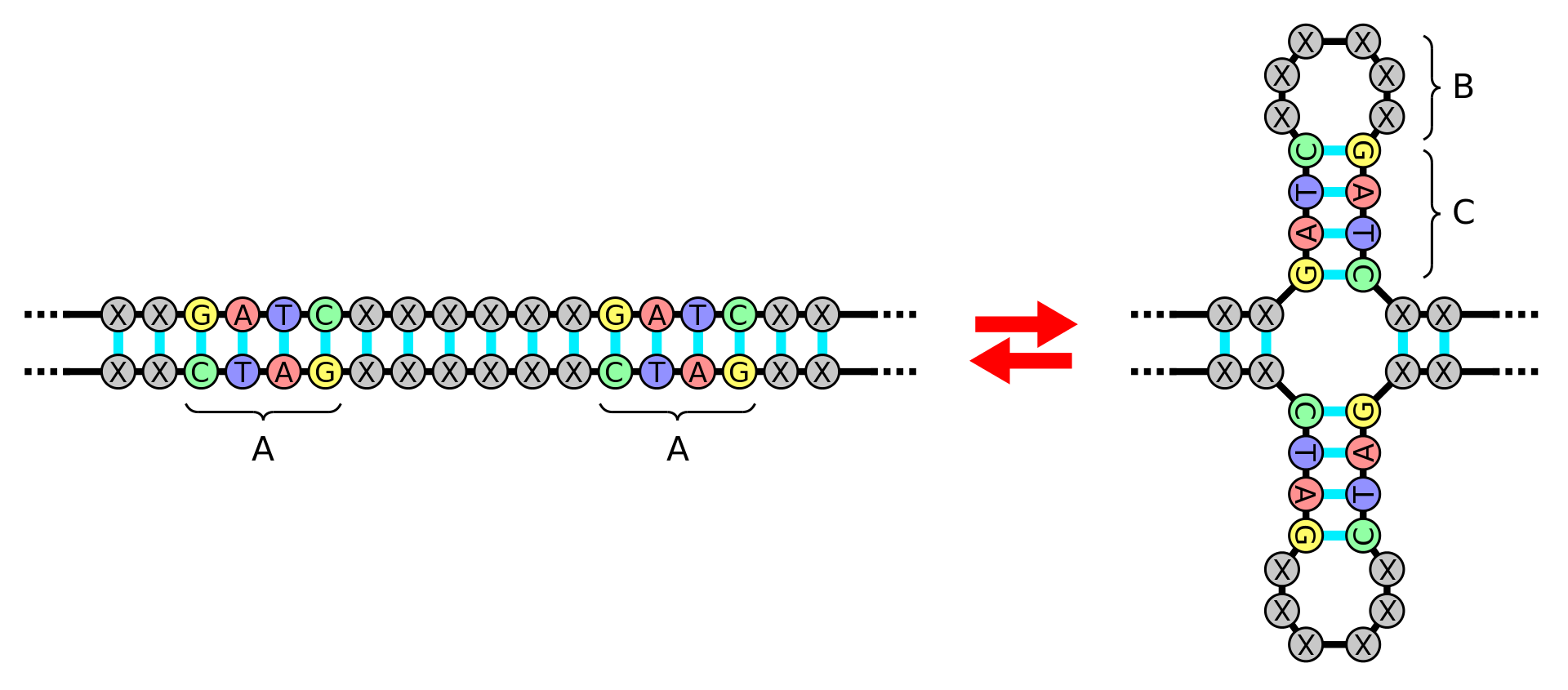
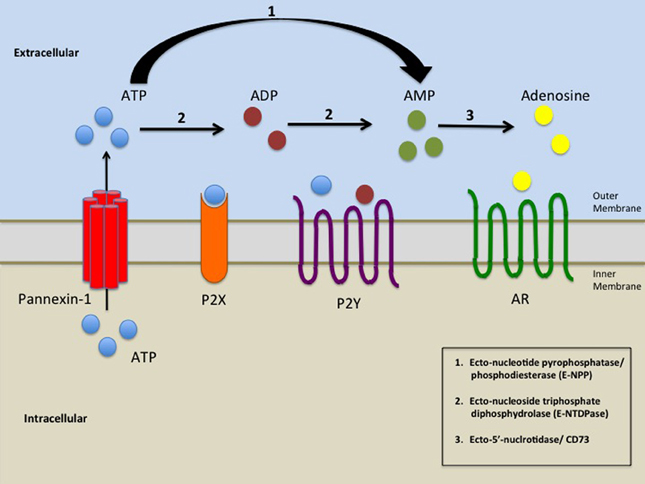
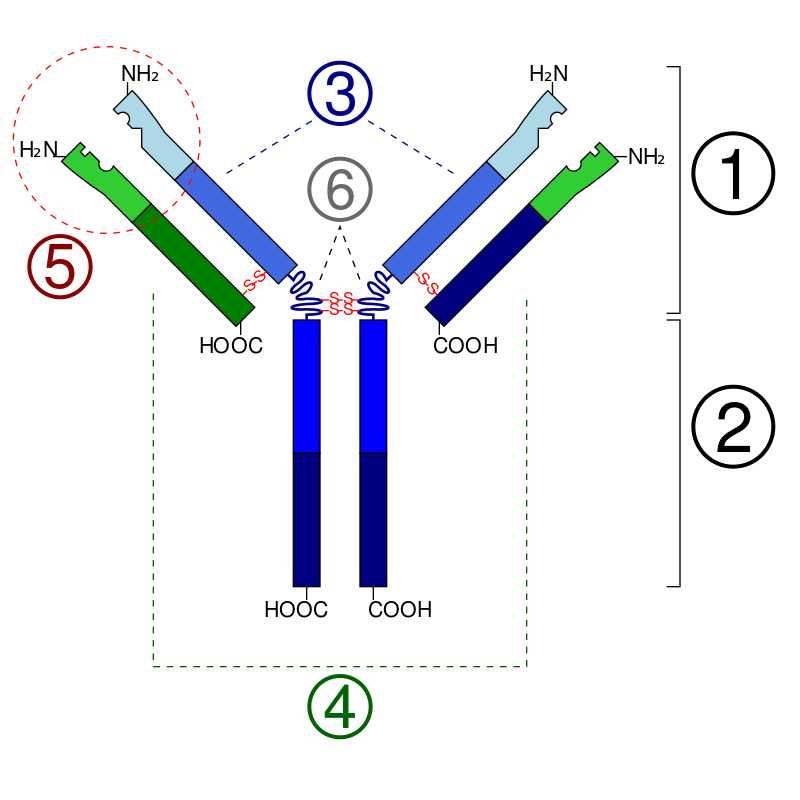
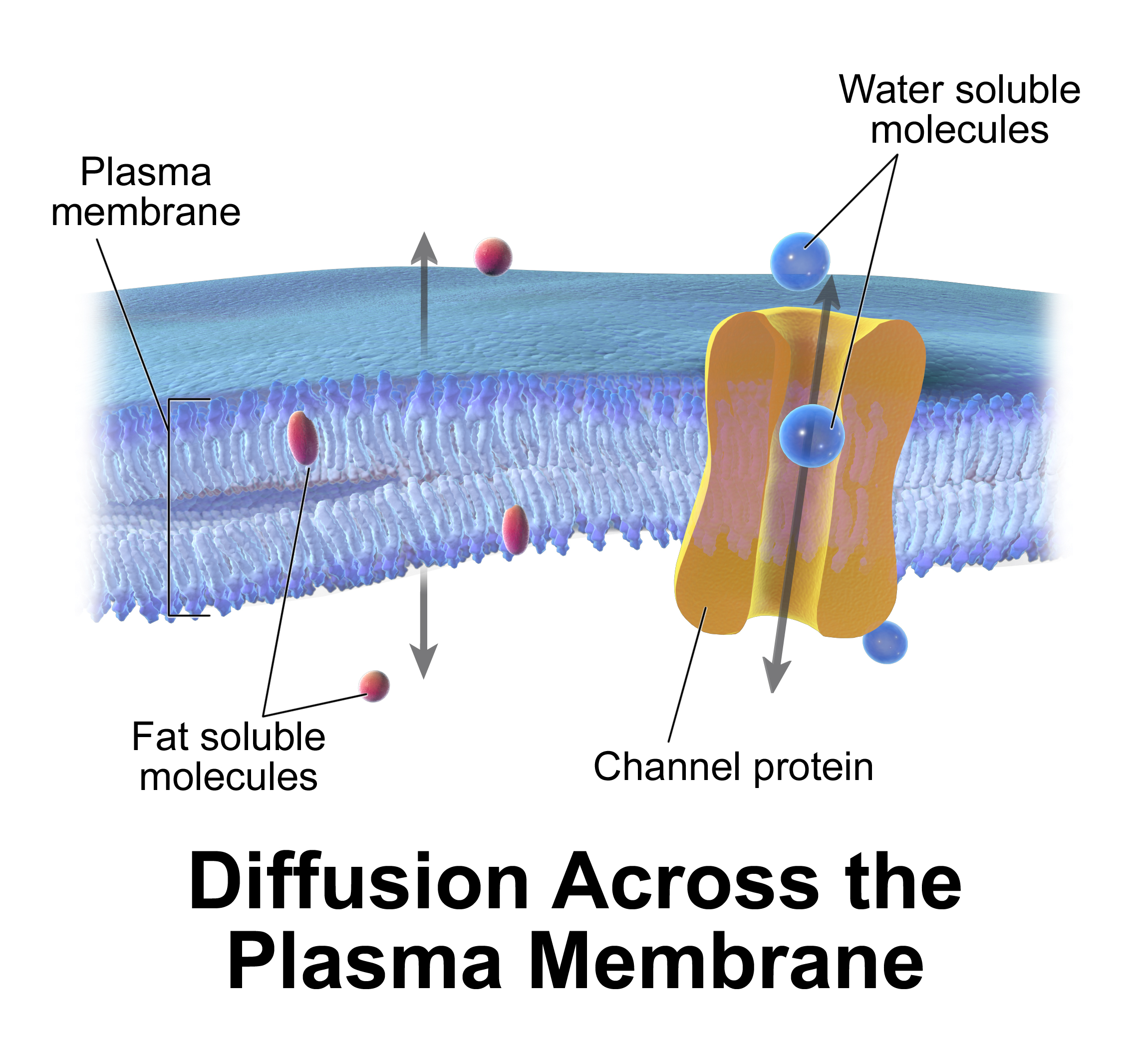
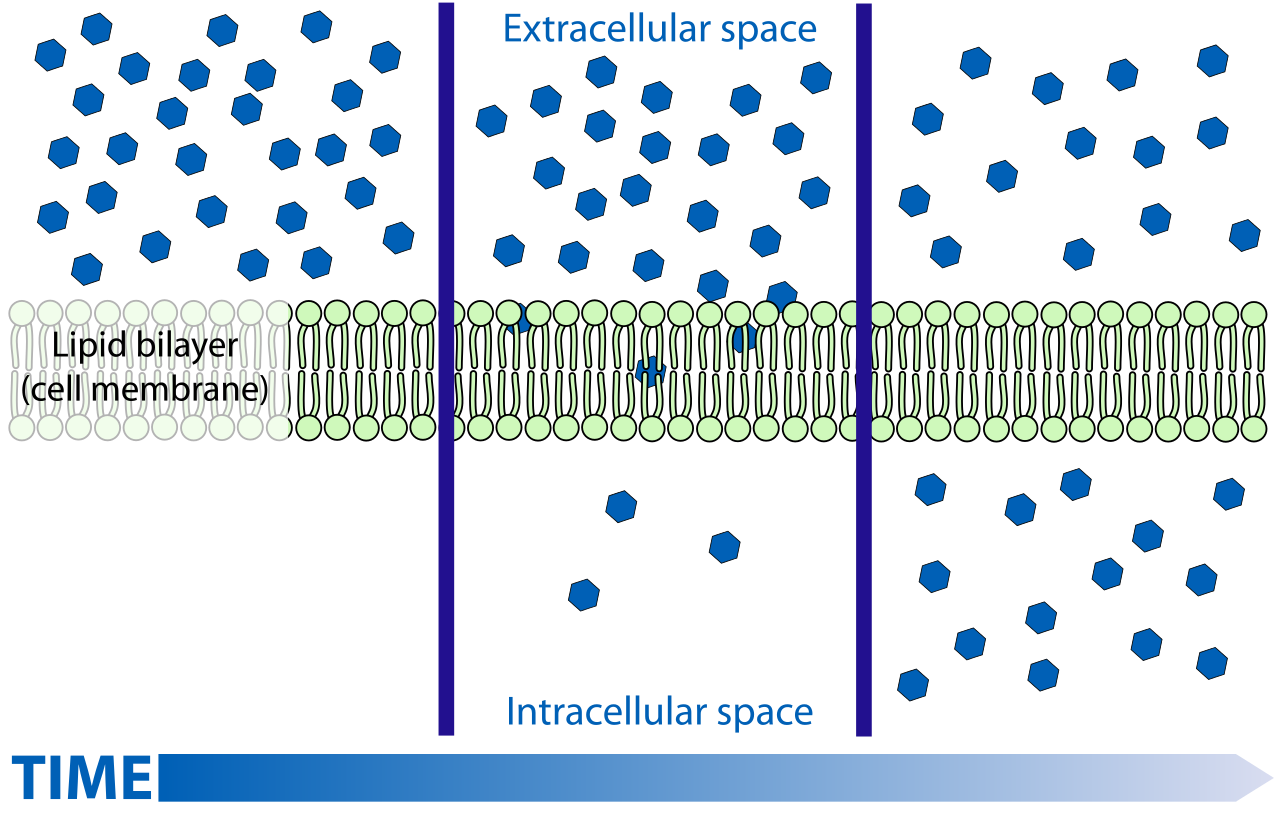
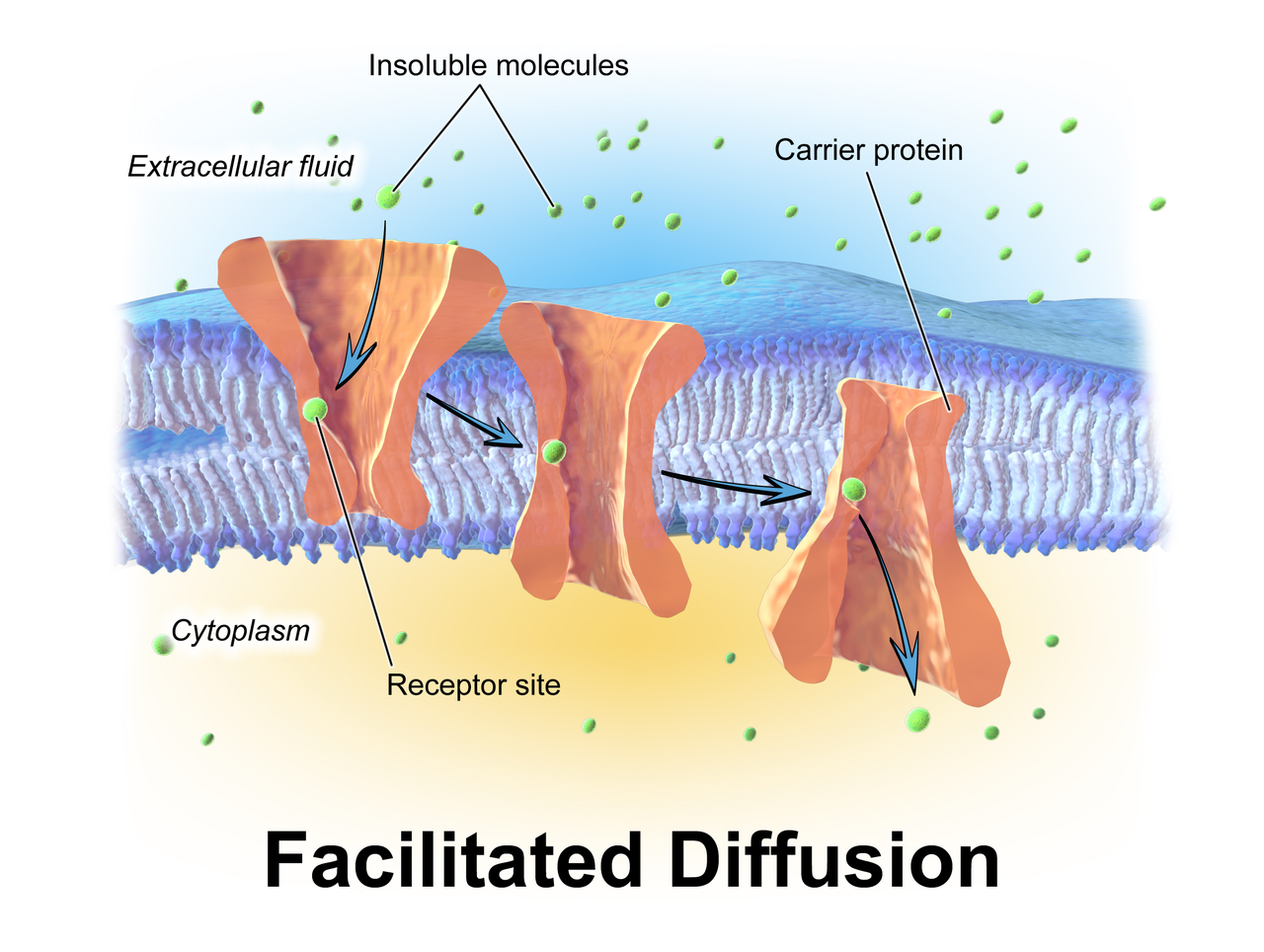
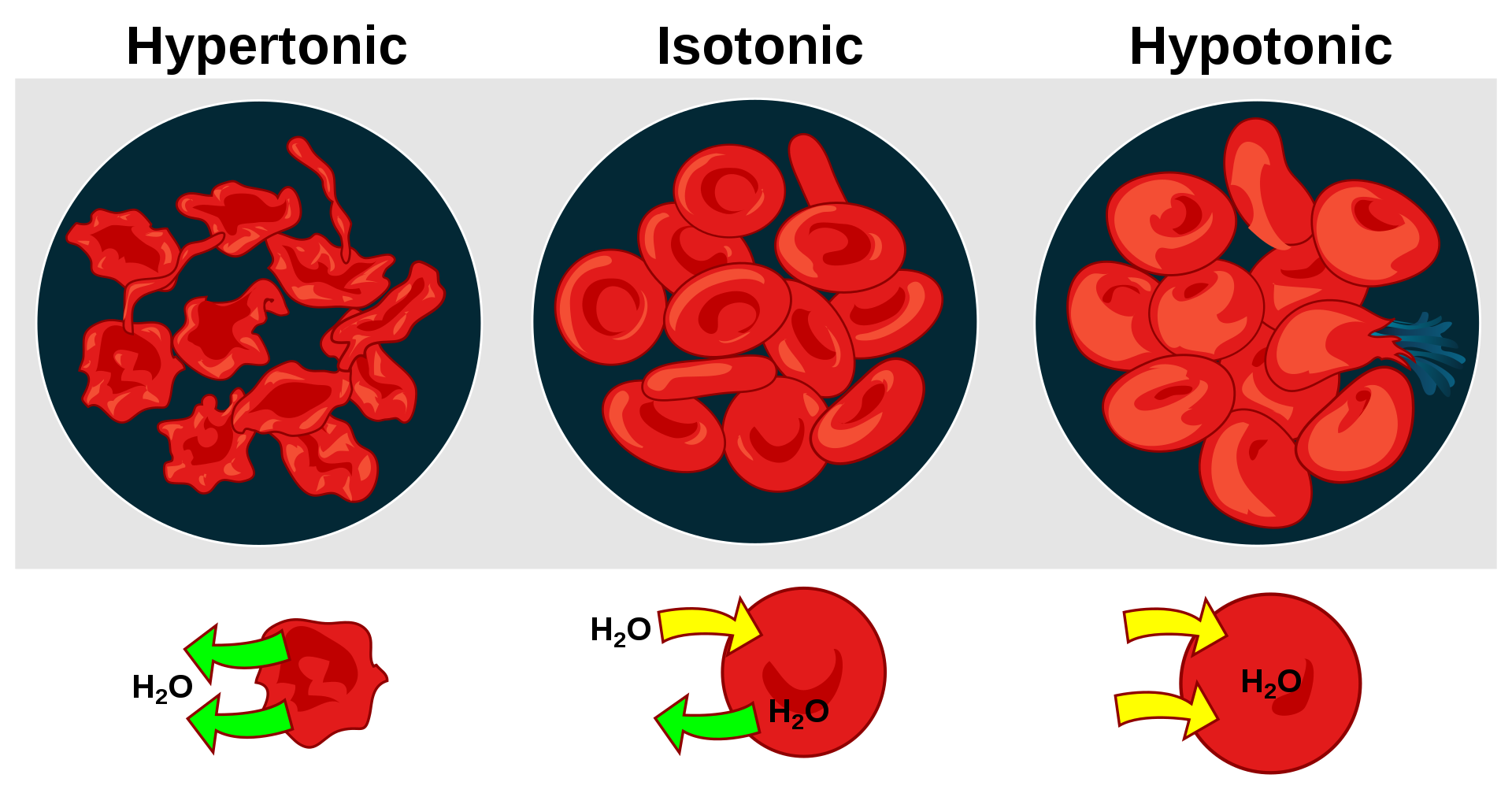
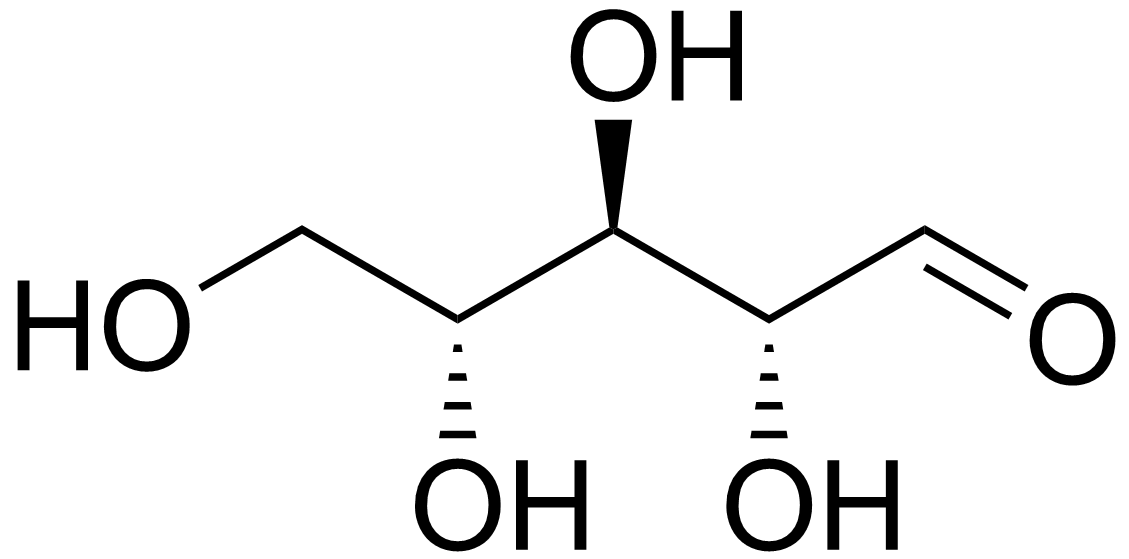
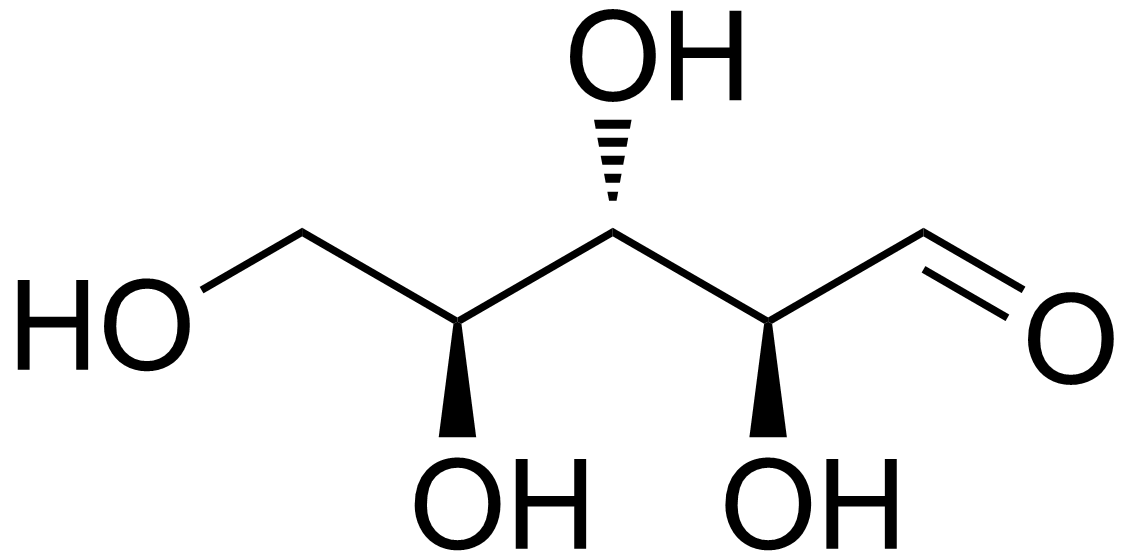
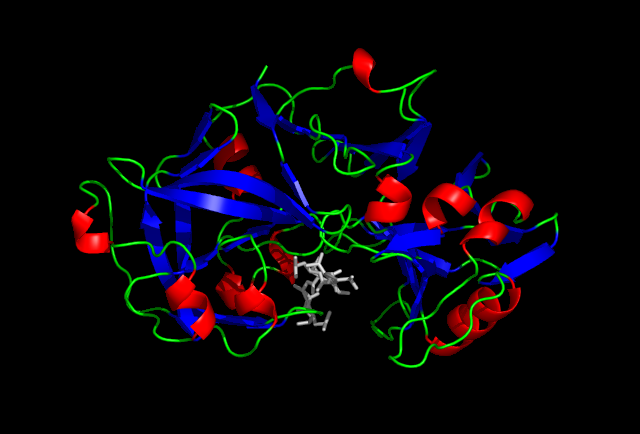
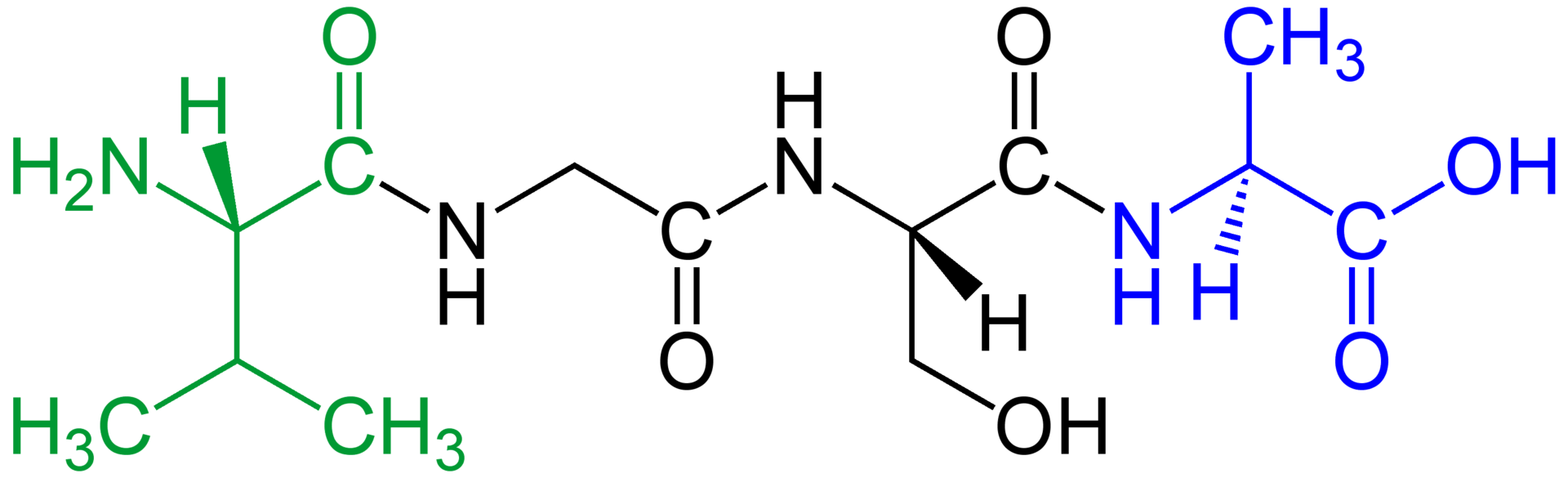
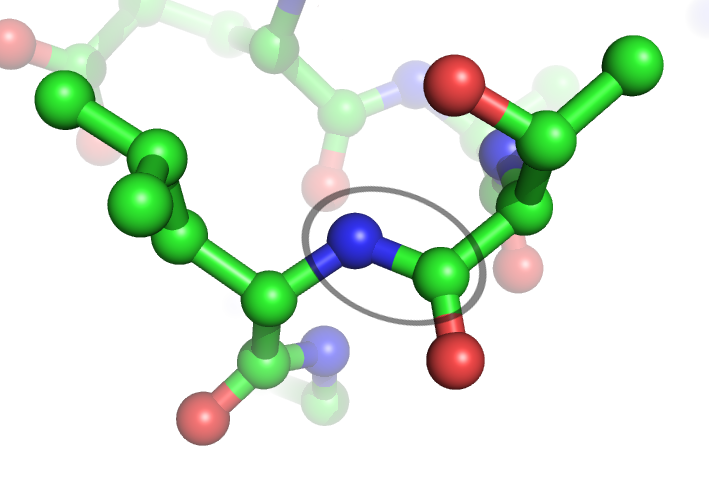
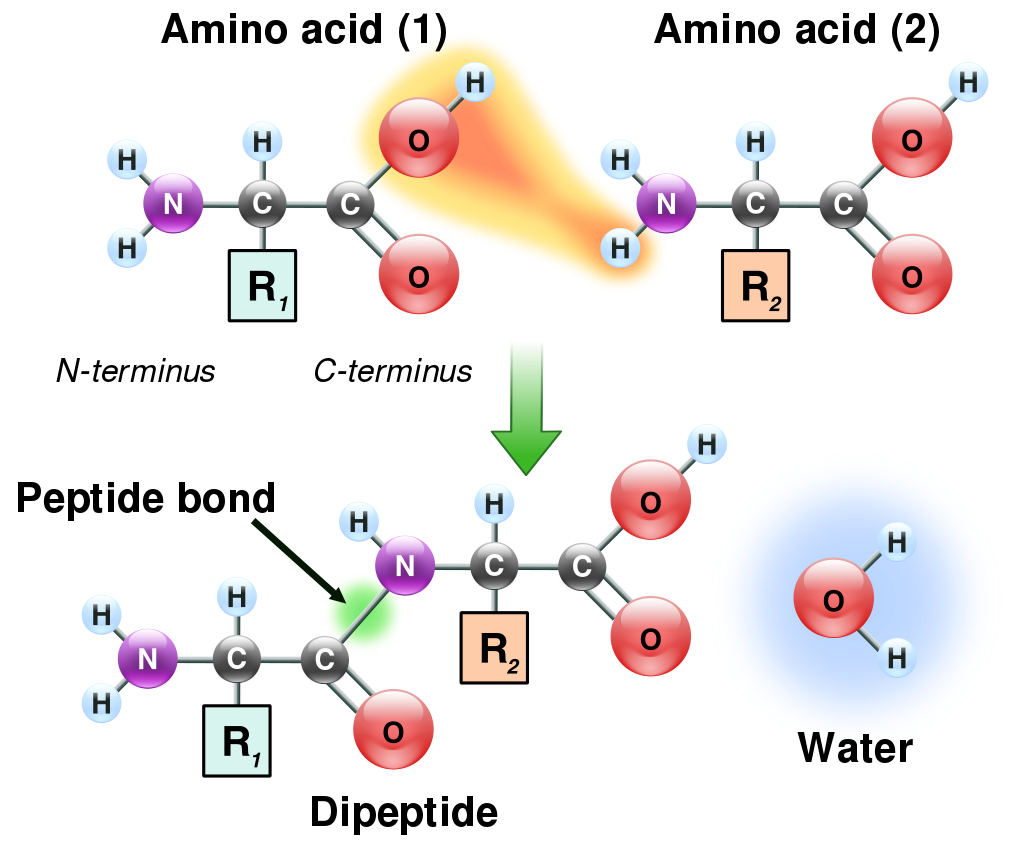
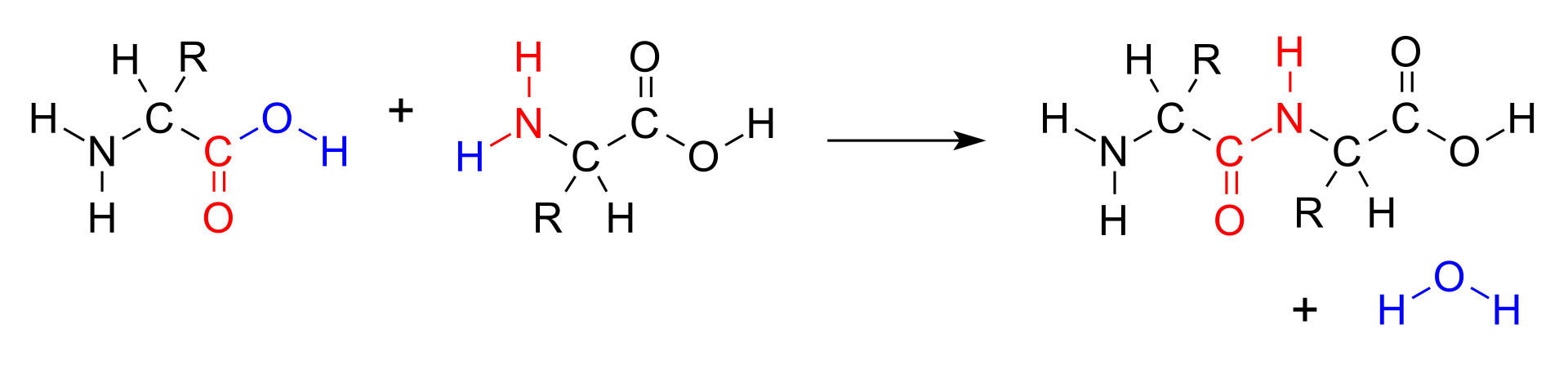
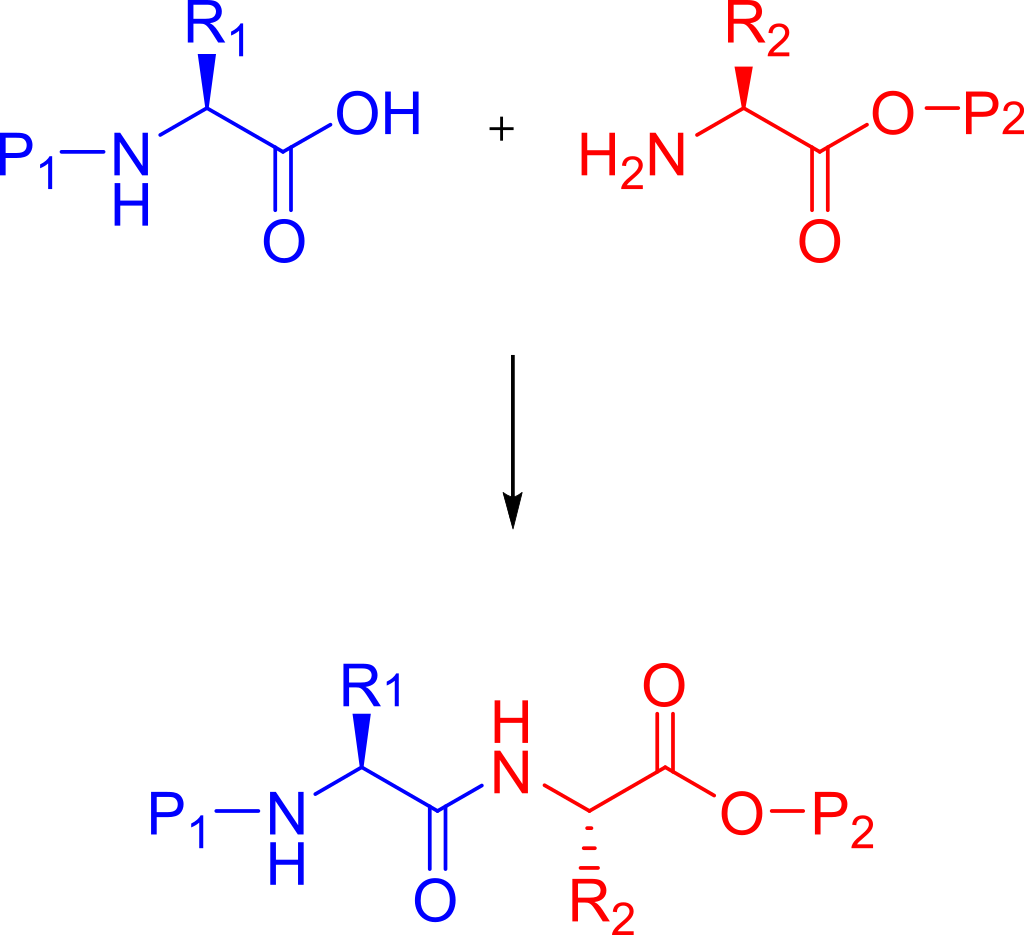
.png)

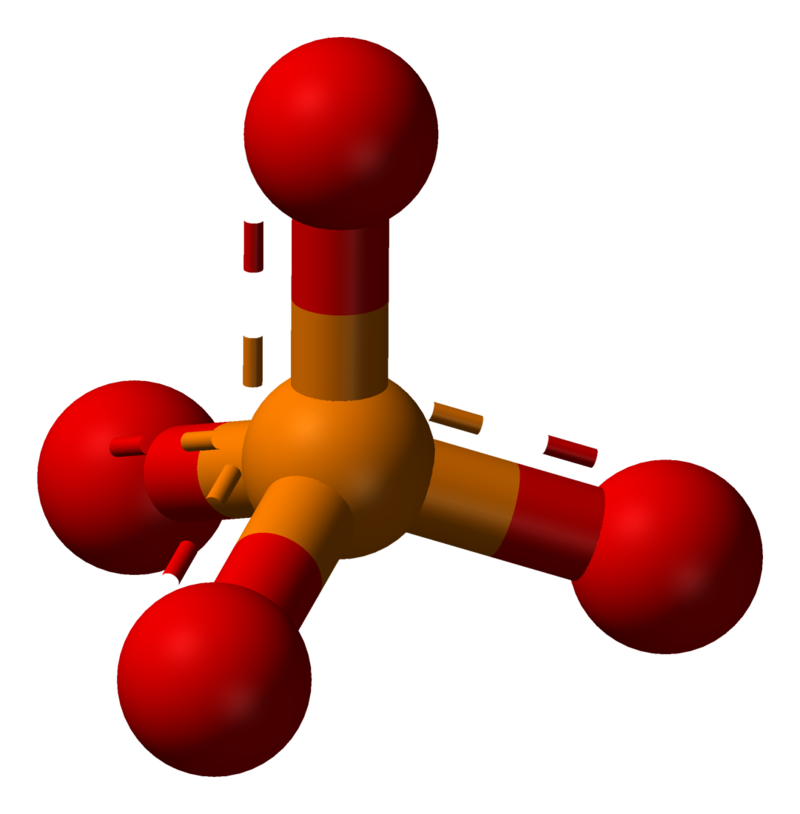
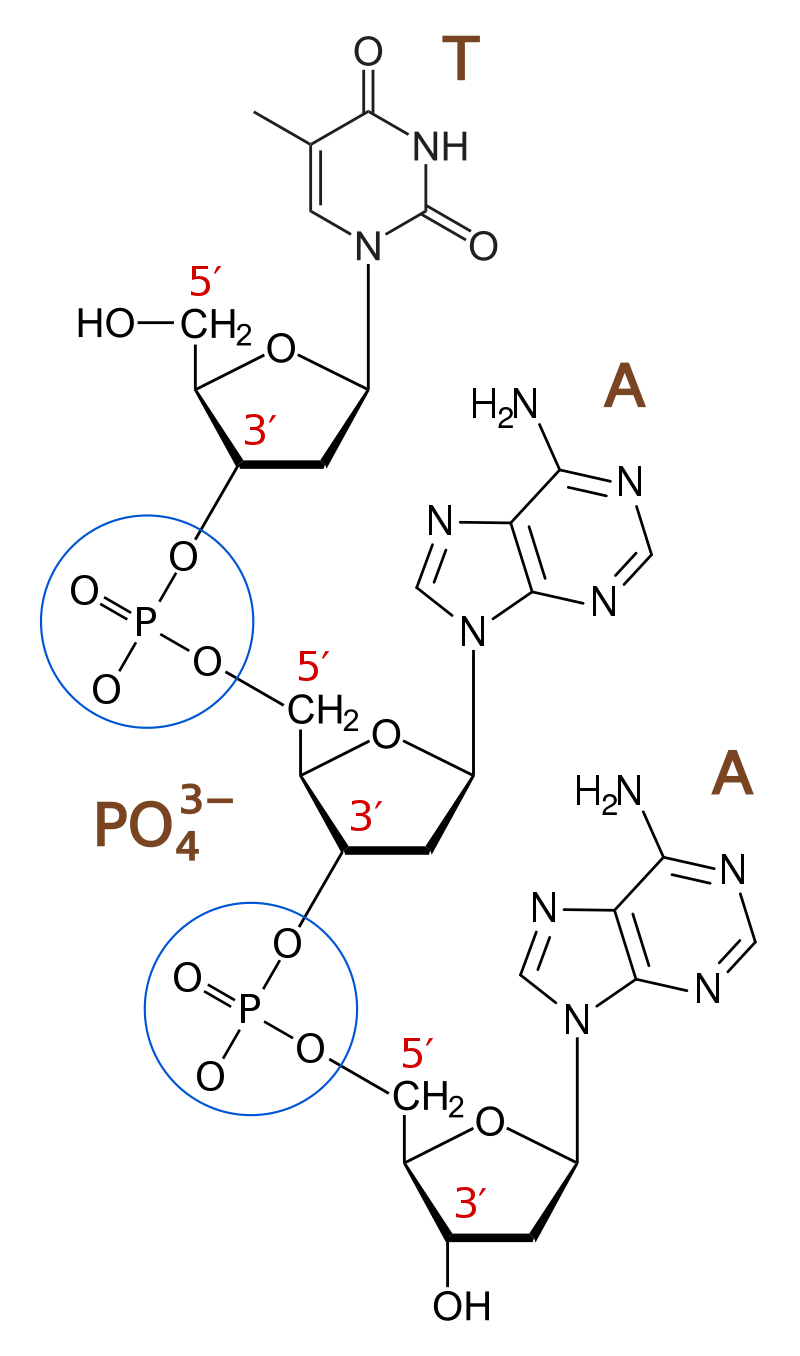
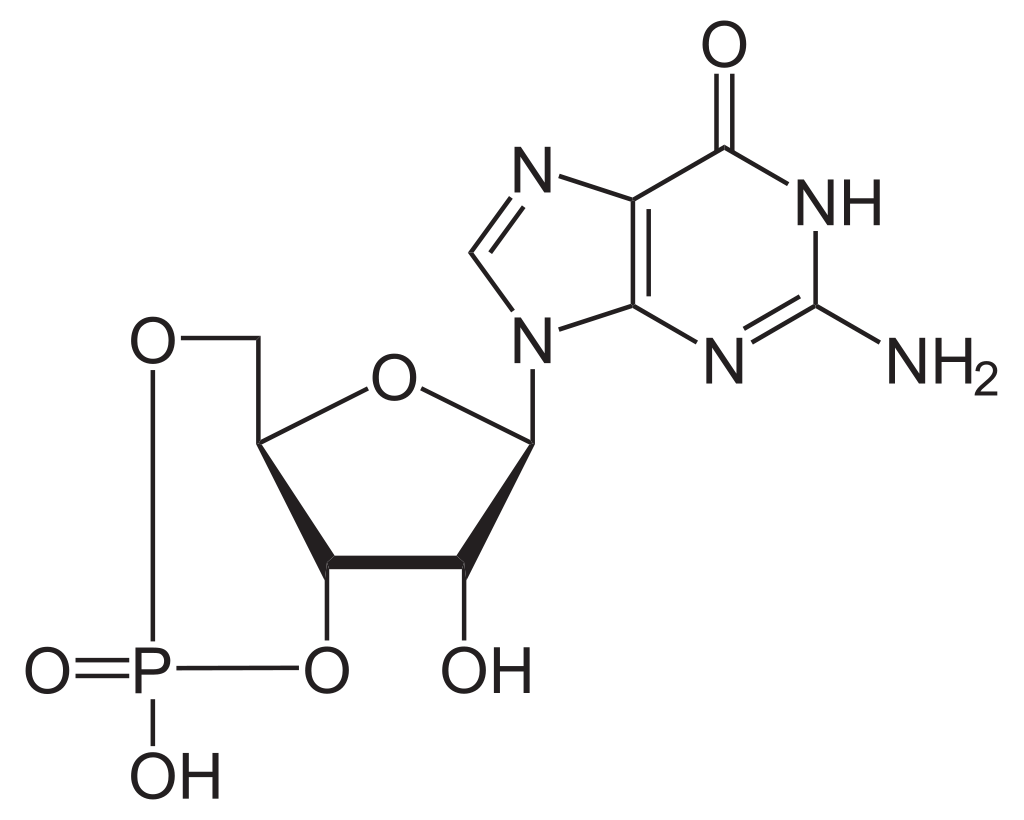

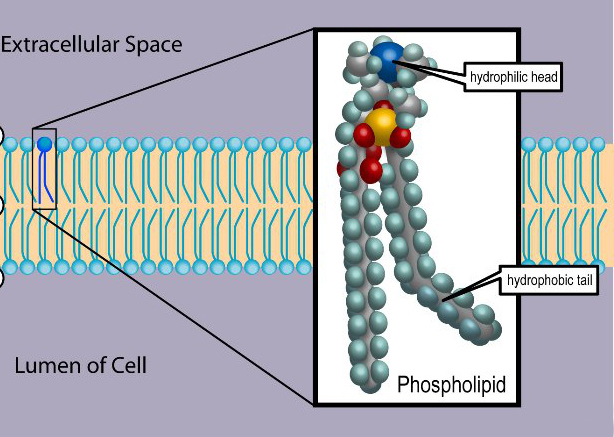
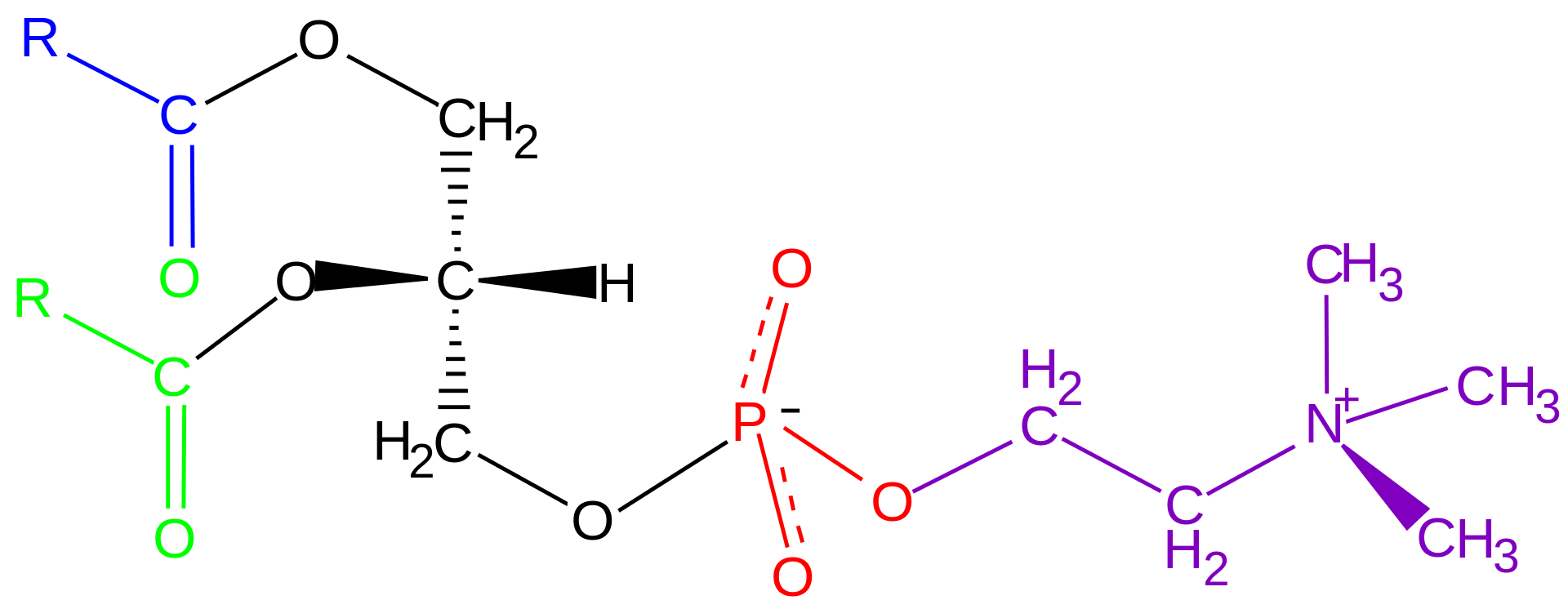
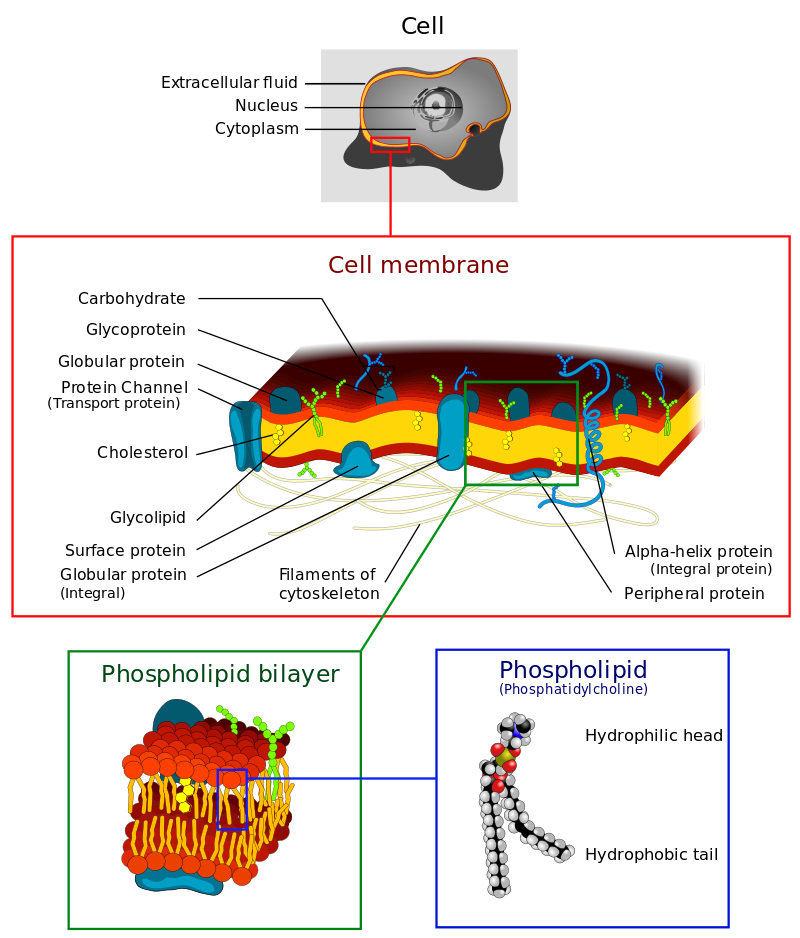
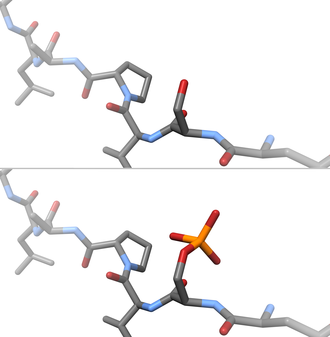
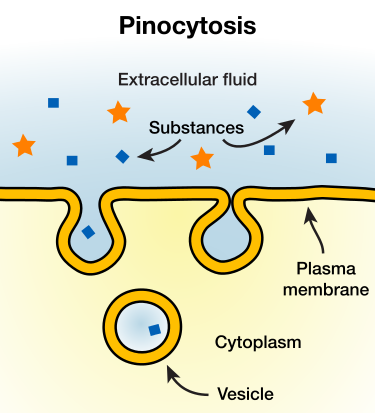
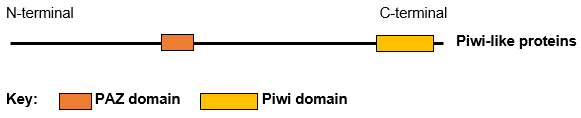
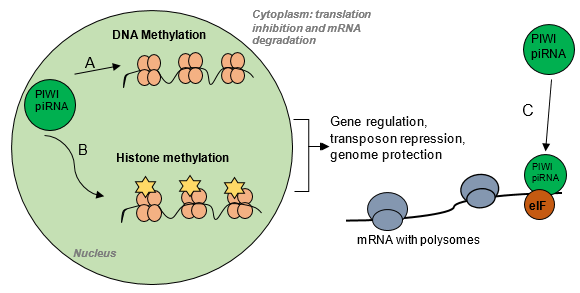

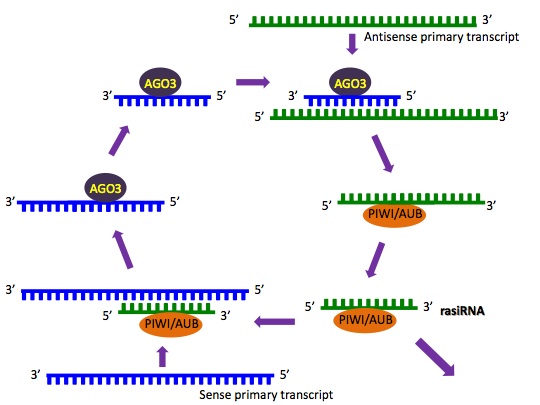

-binding_protein.png)


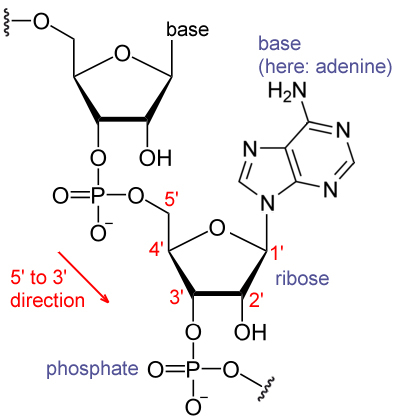
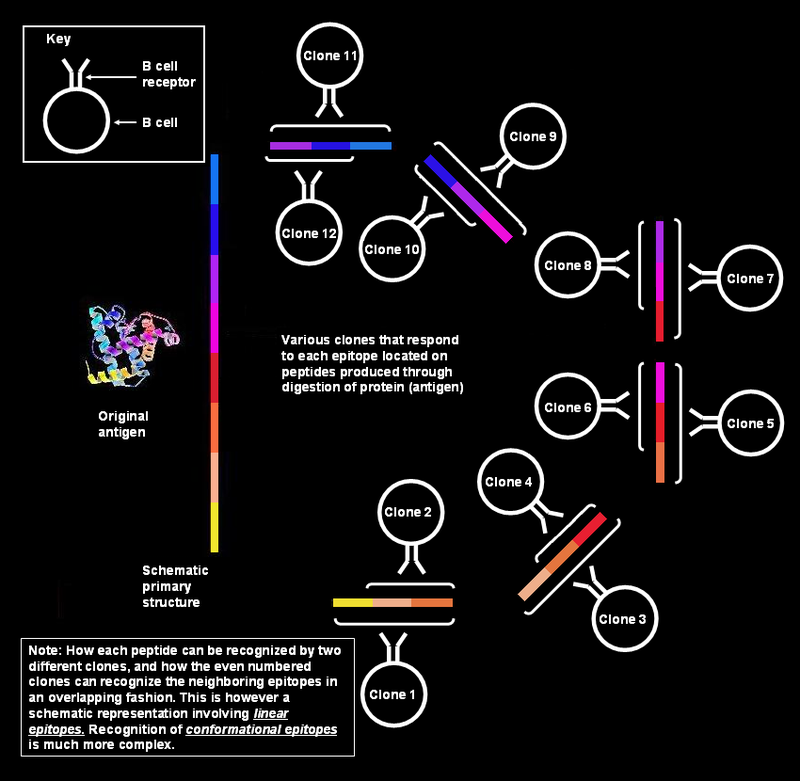
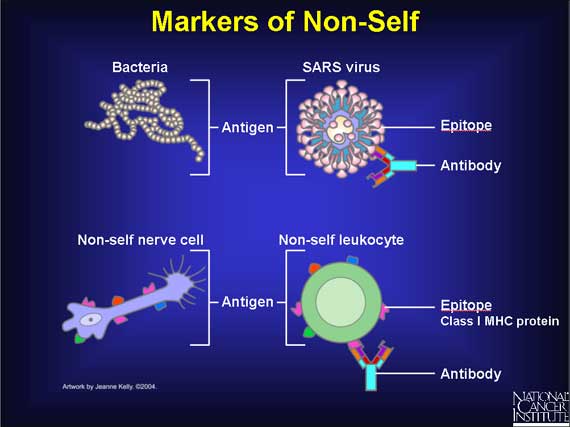
.png)
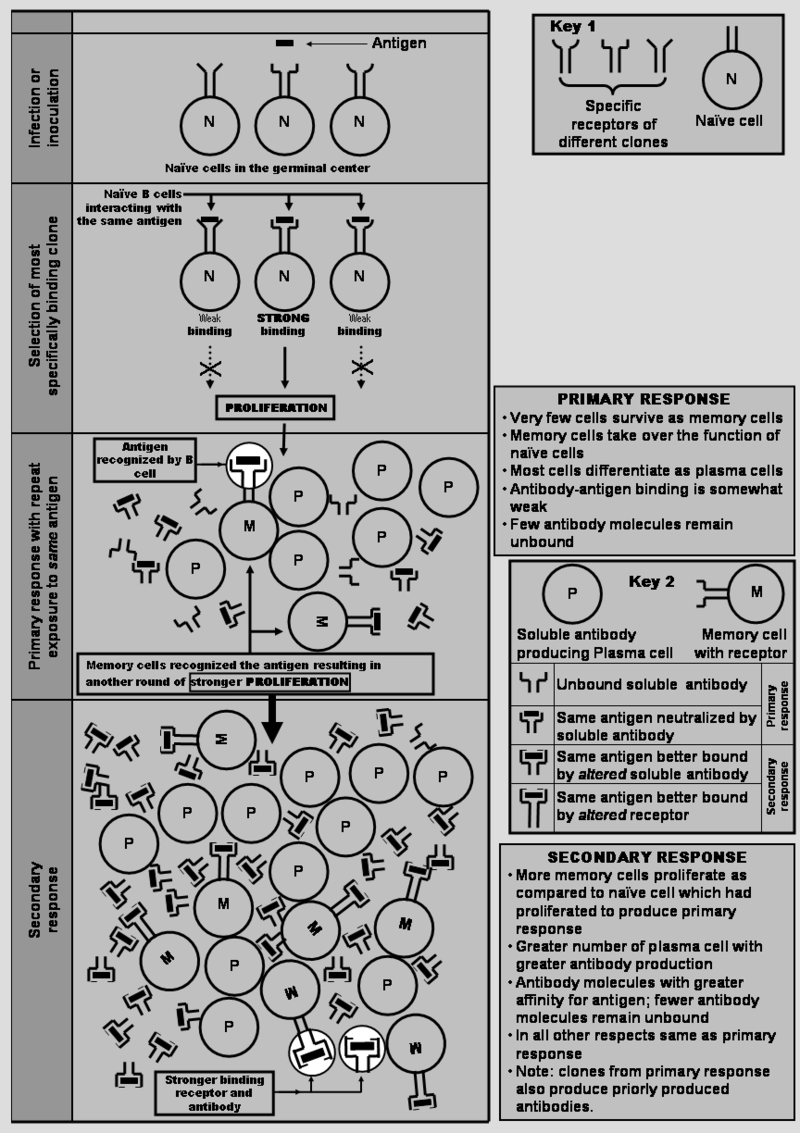
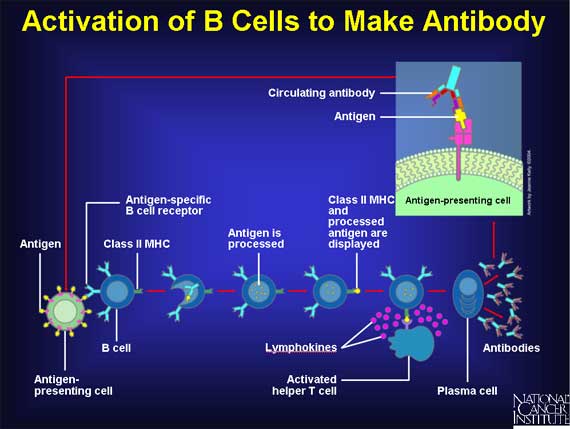
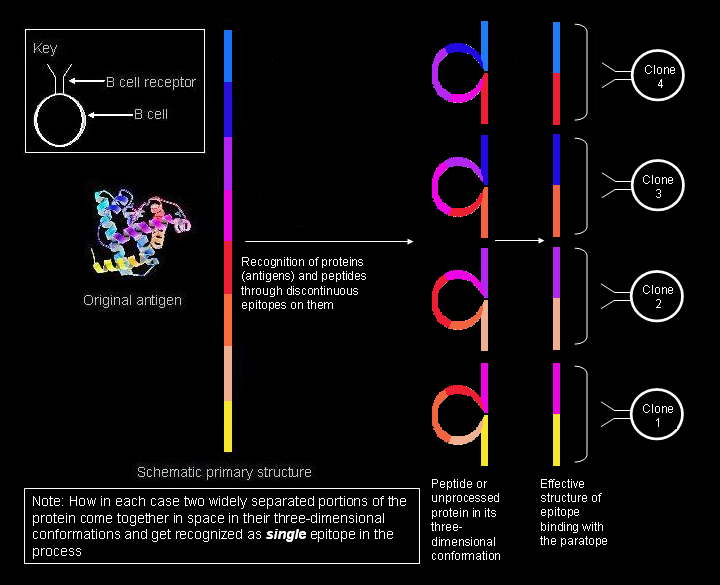
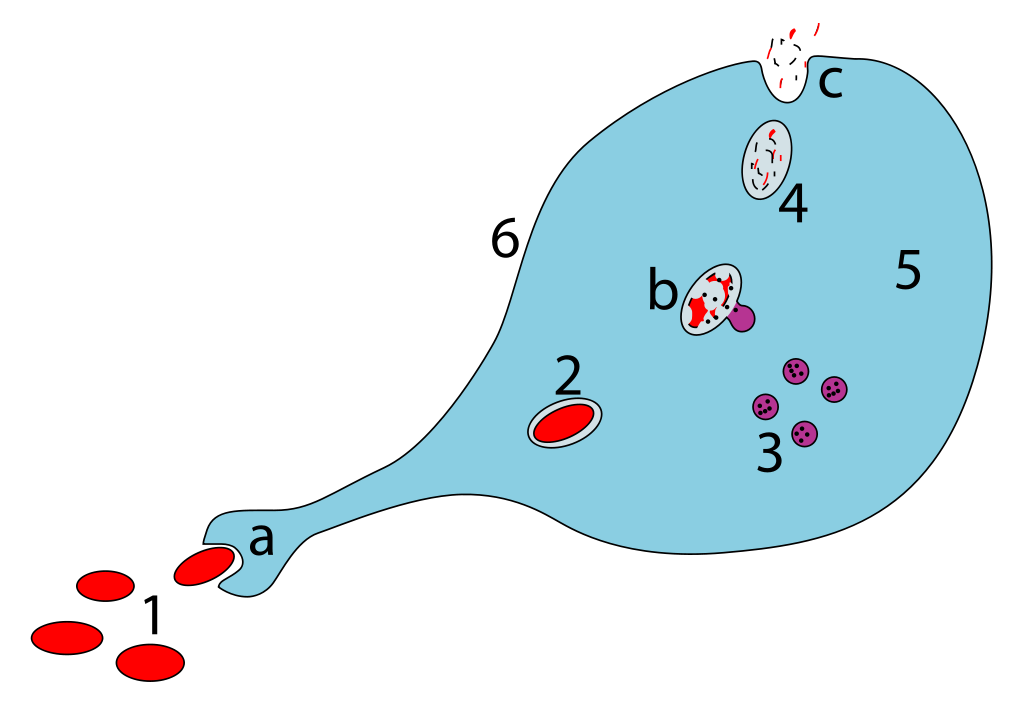
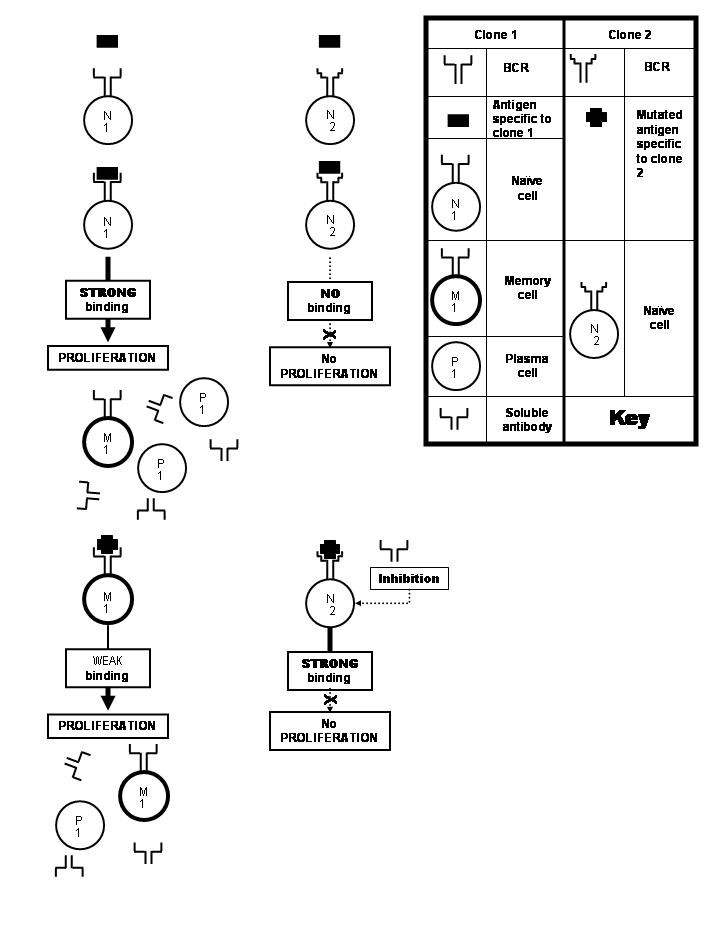

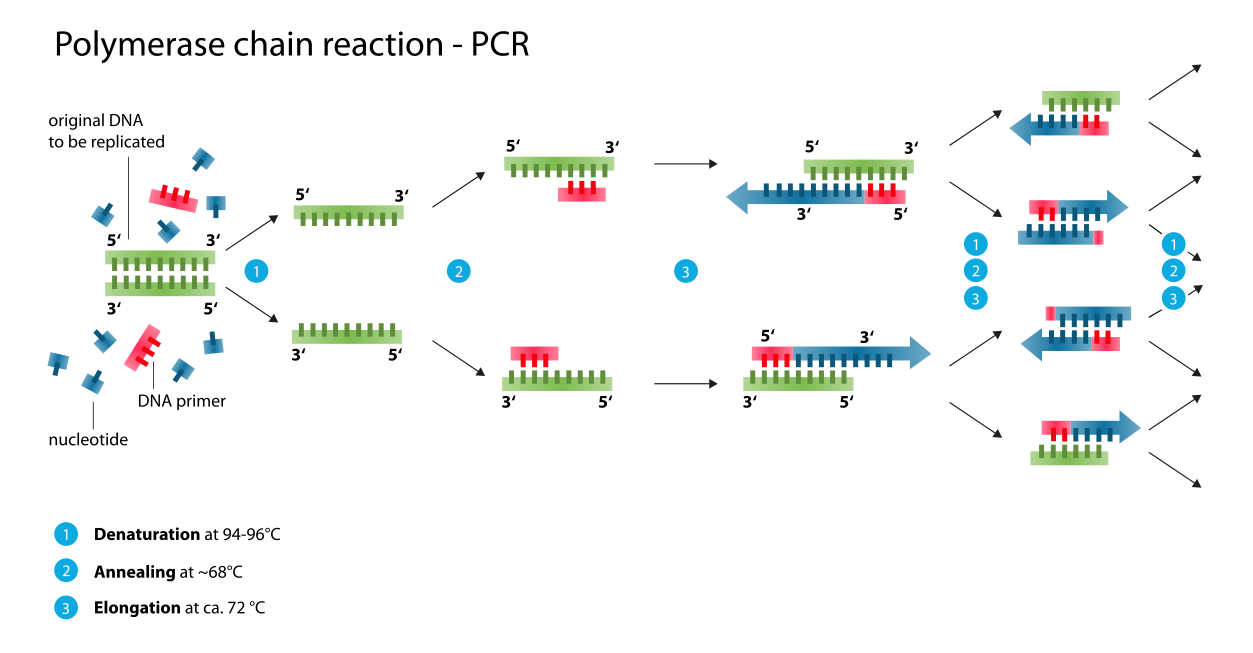
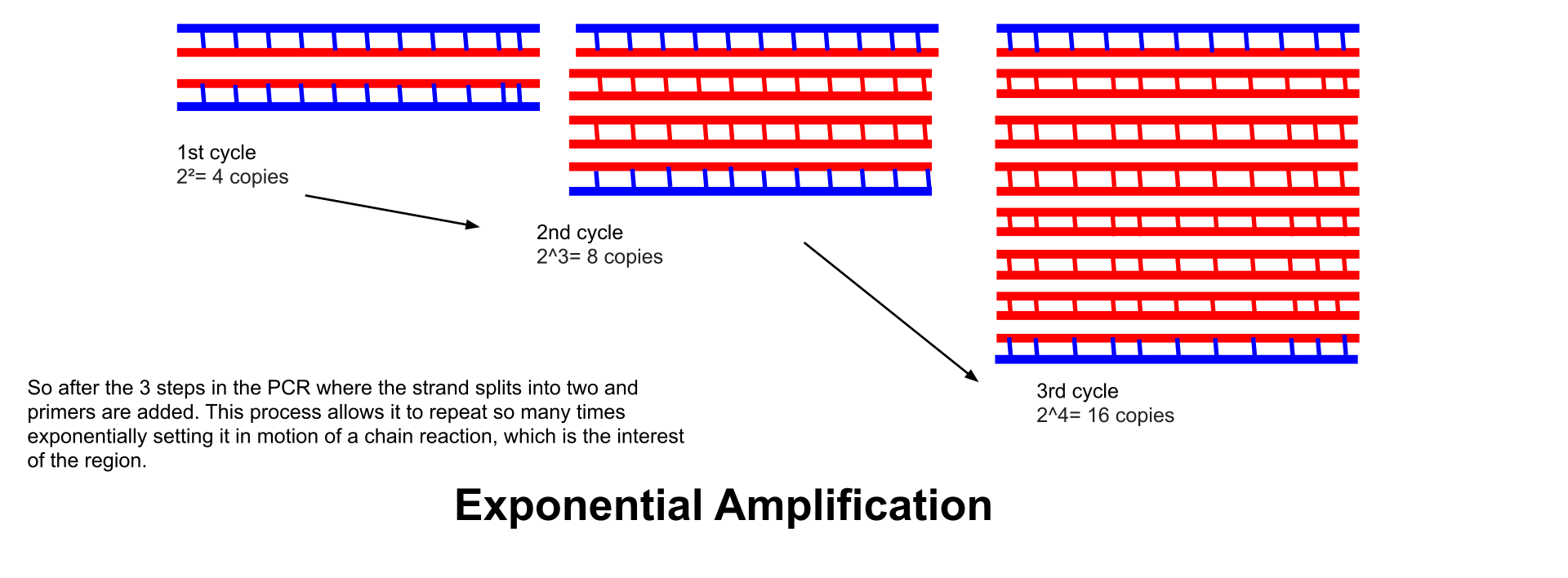
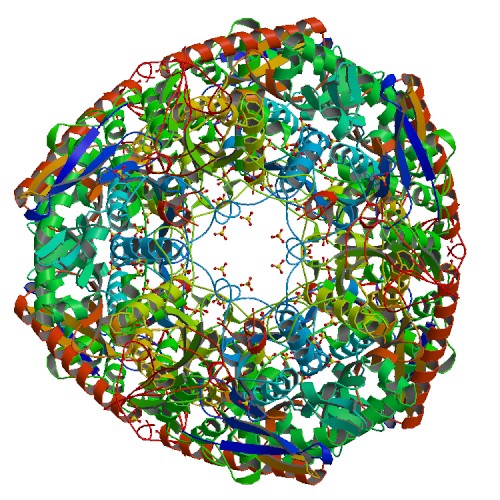
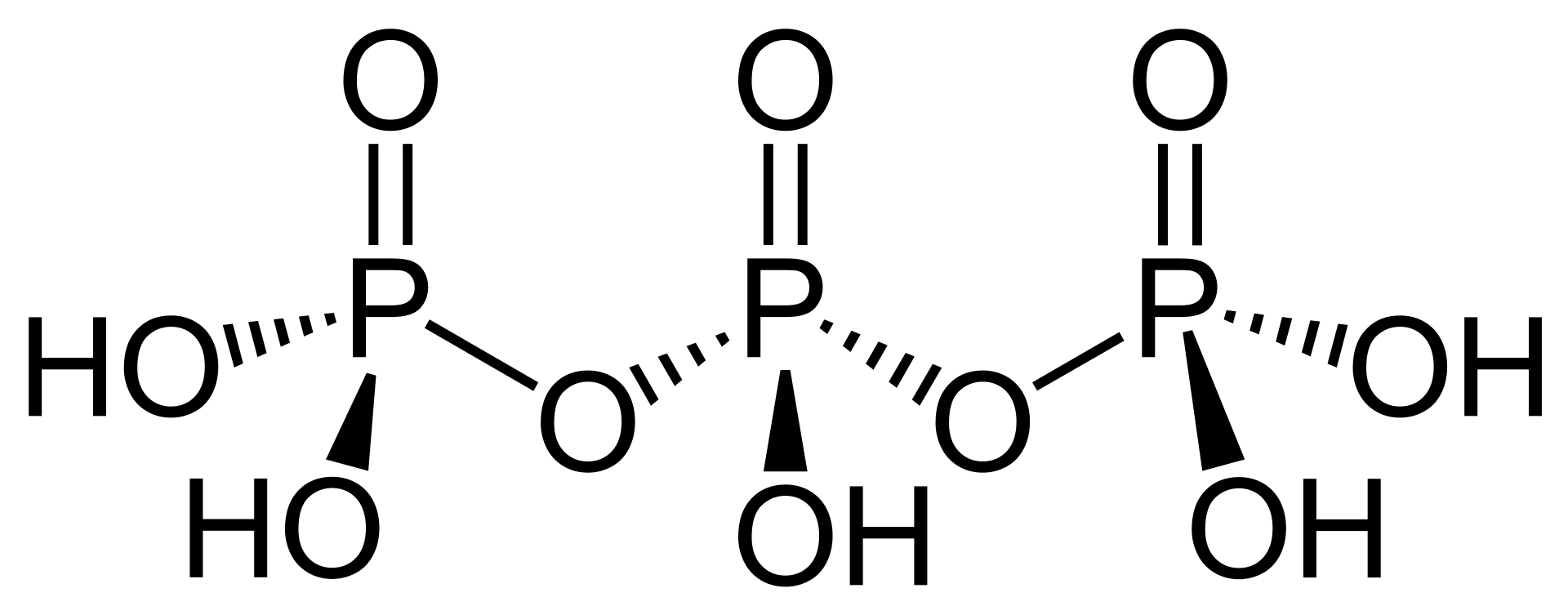
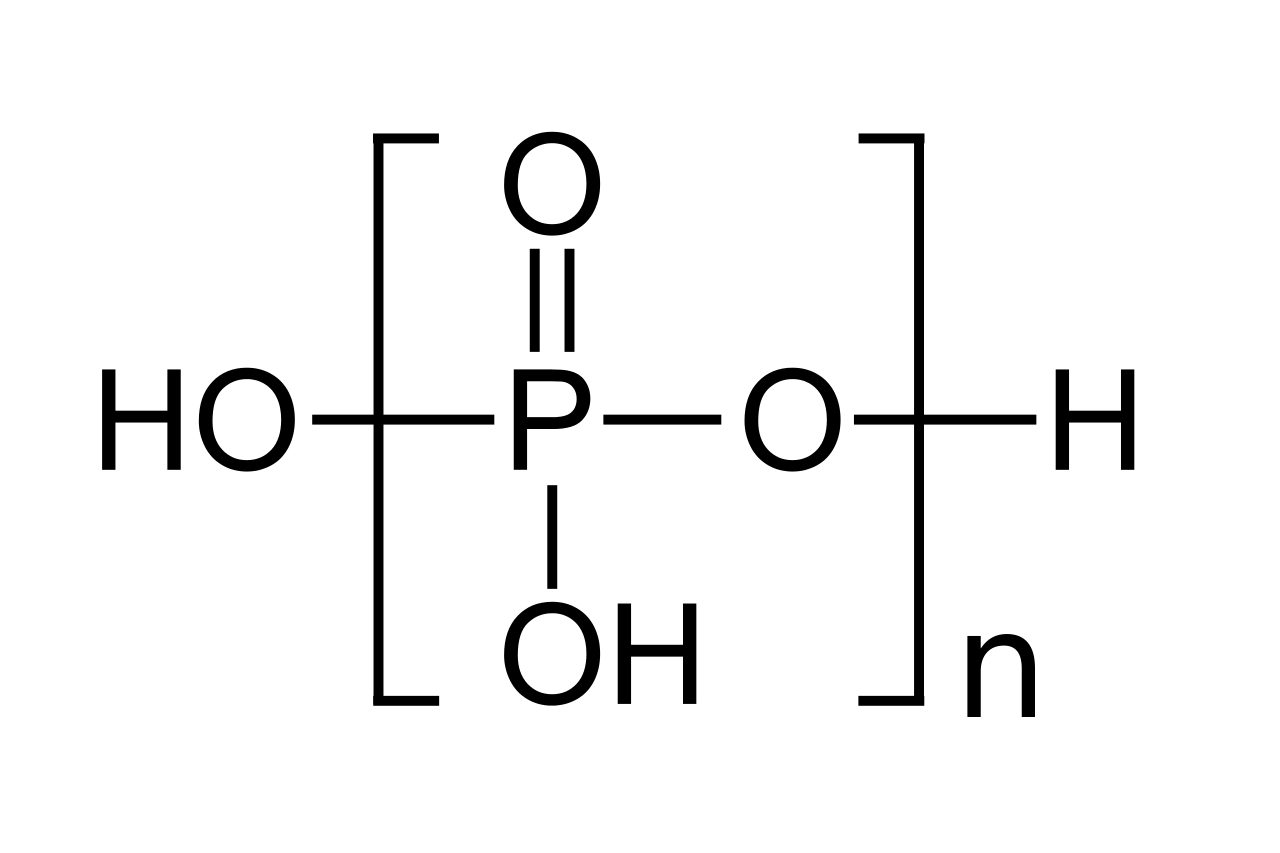
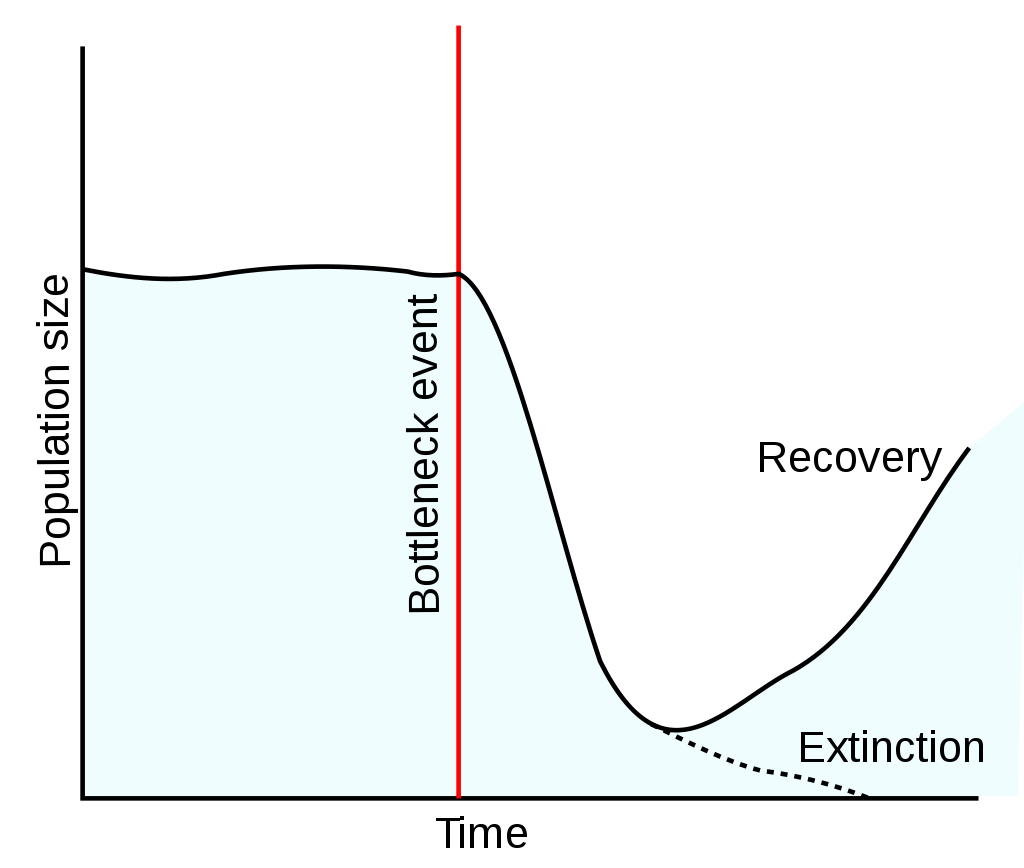
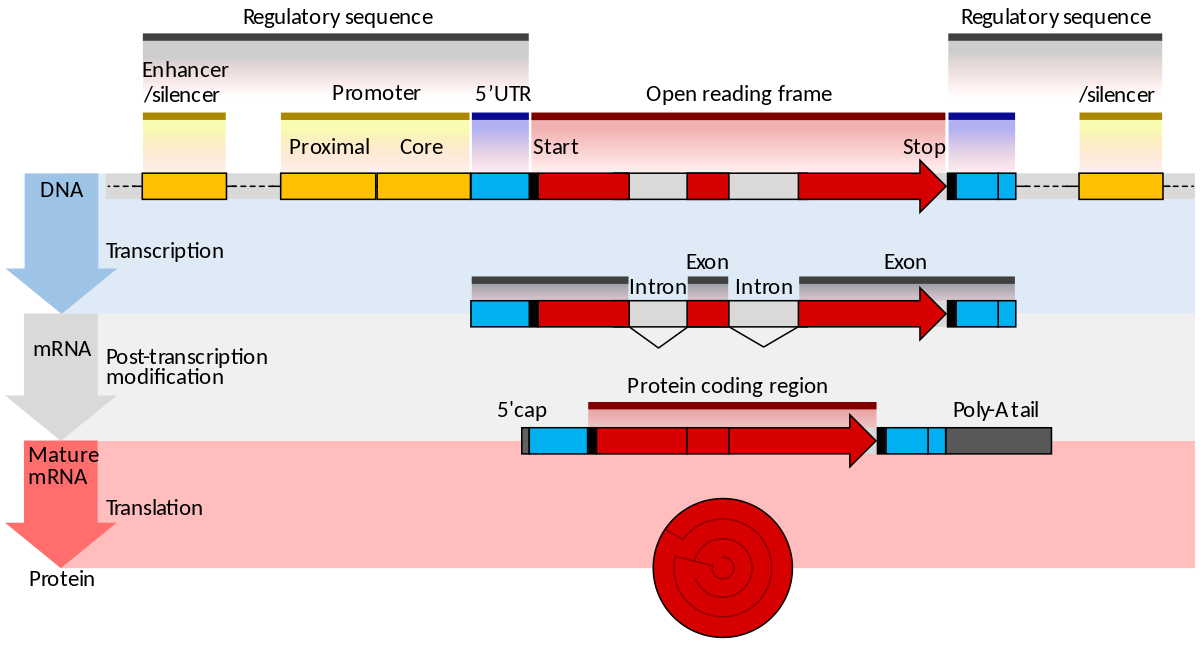
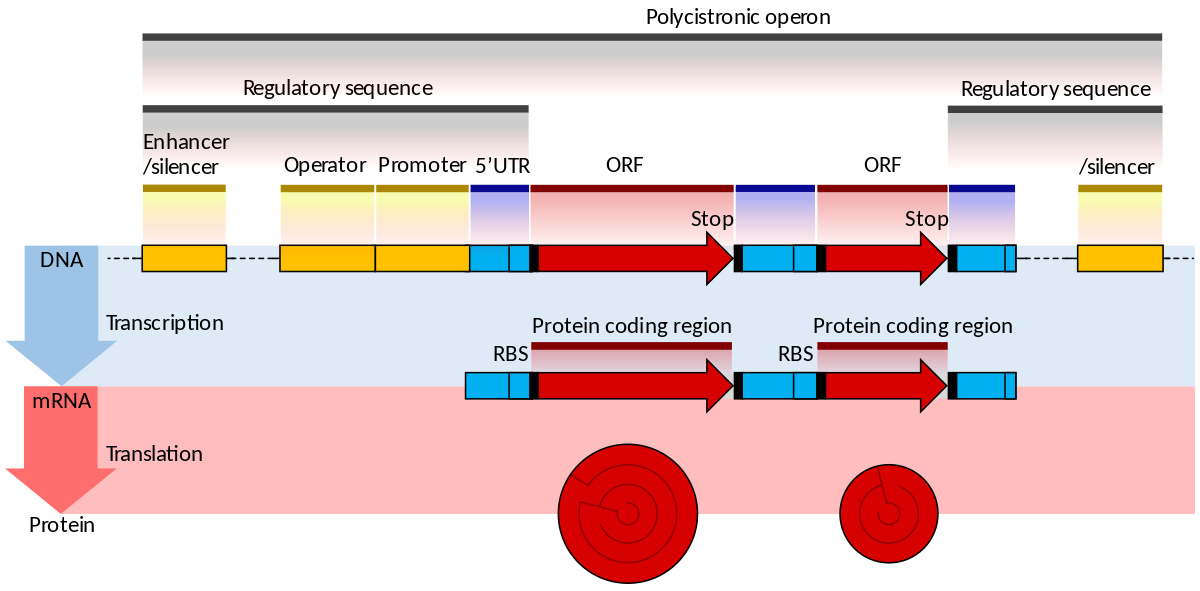
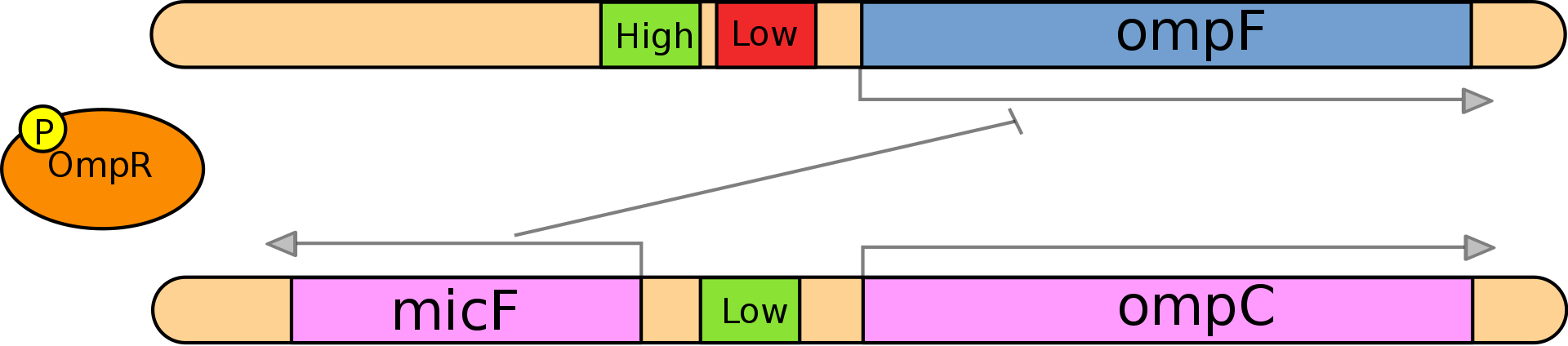

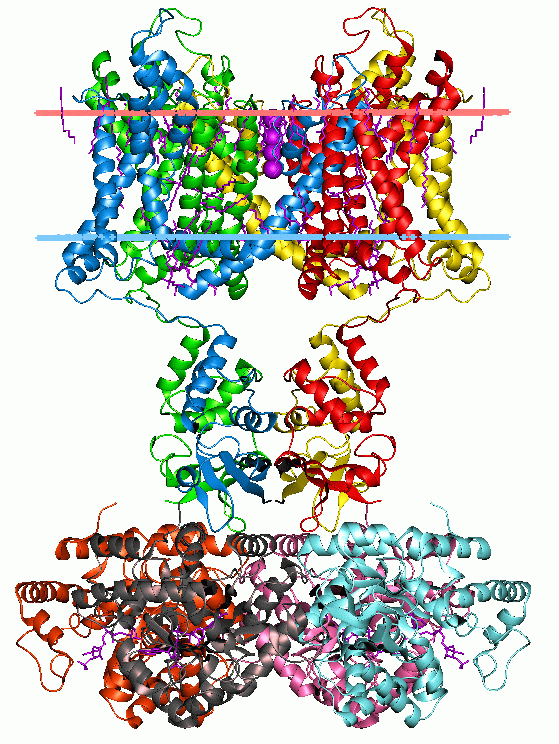
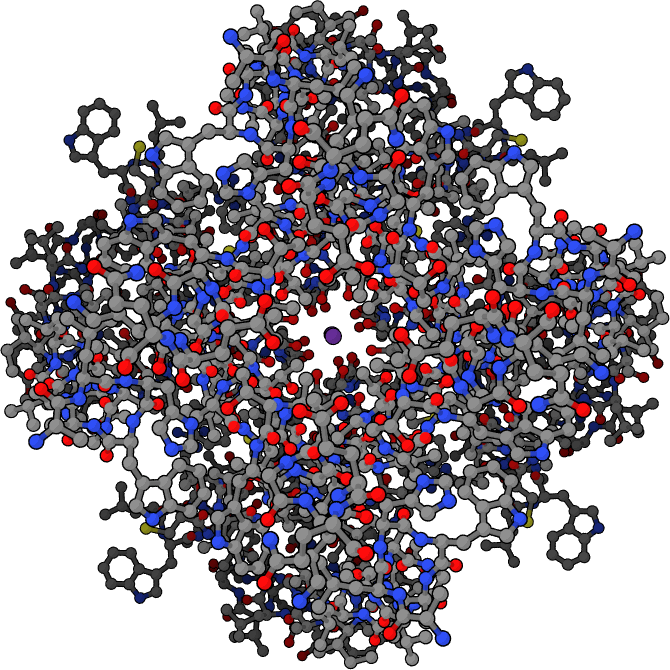
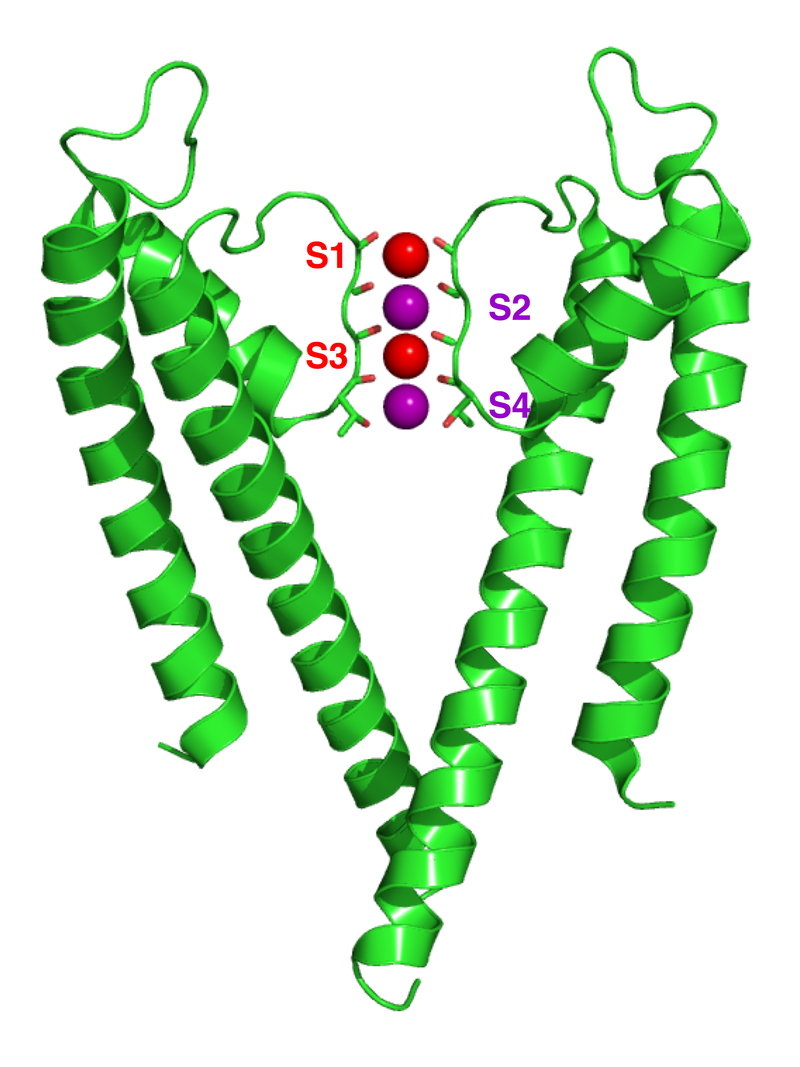
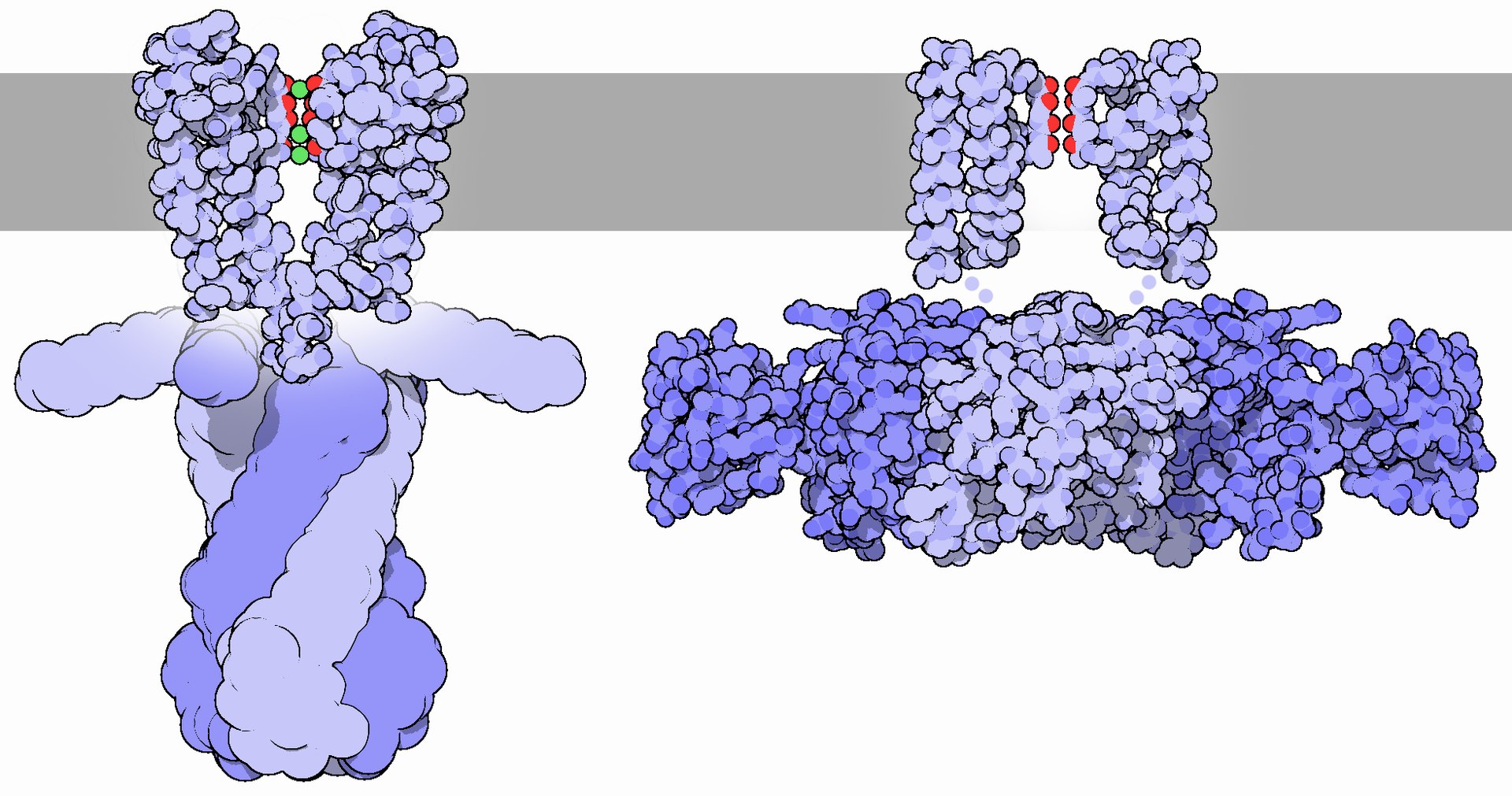
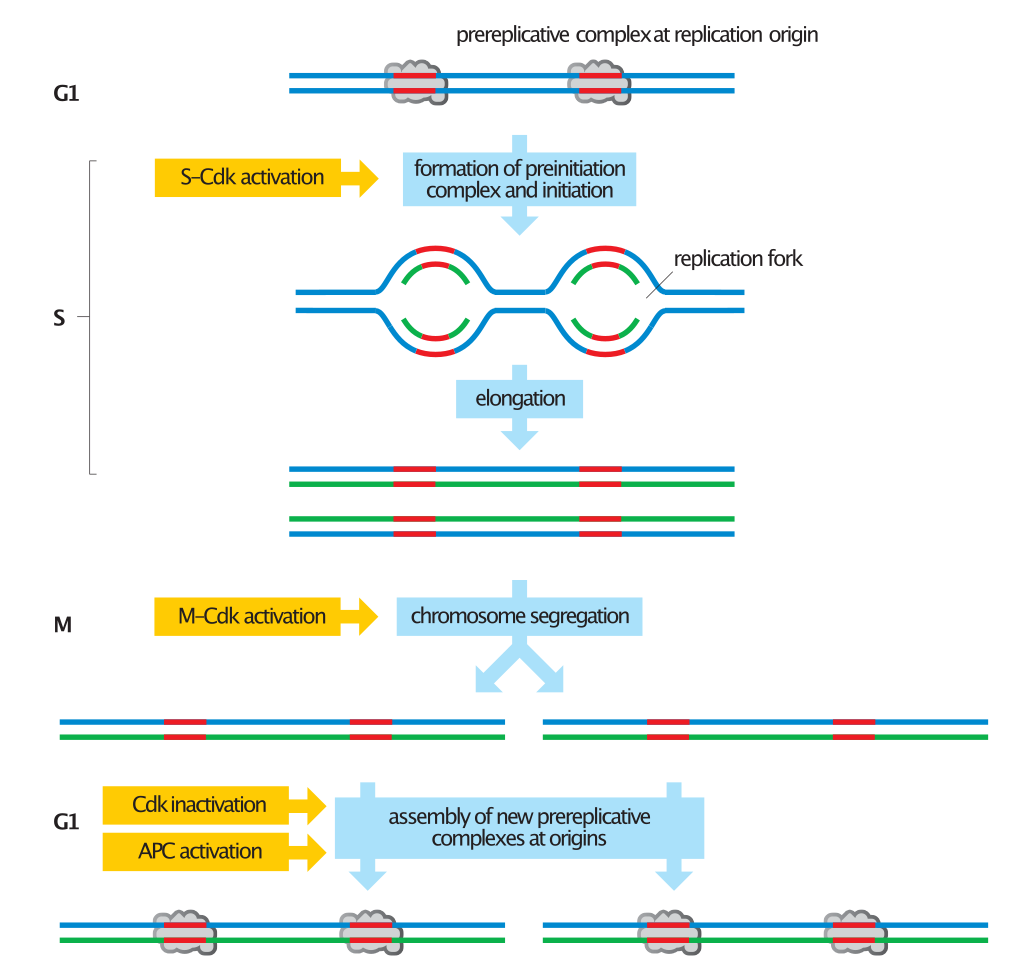
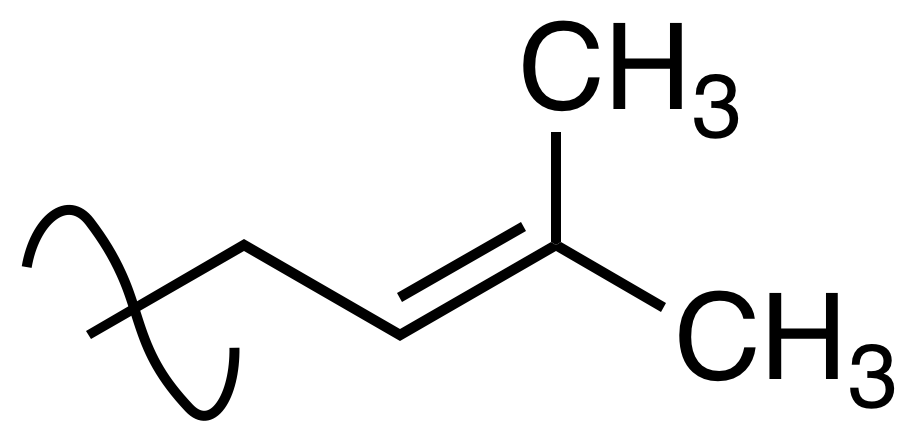
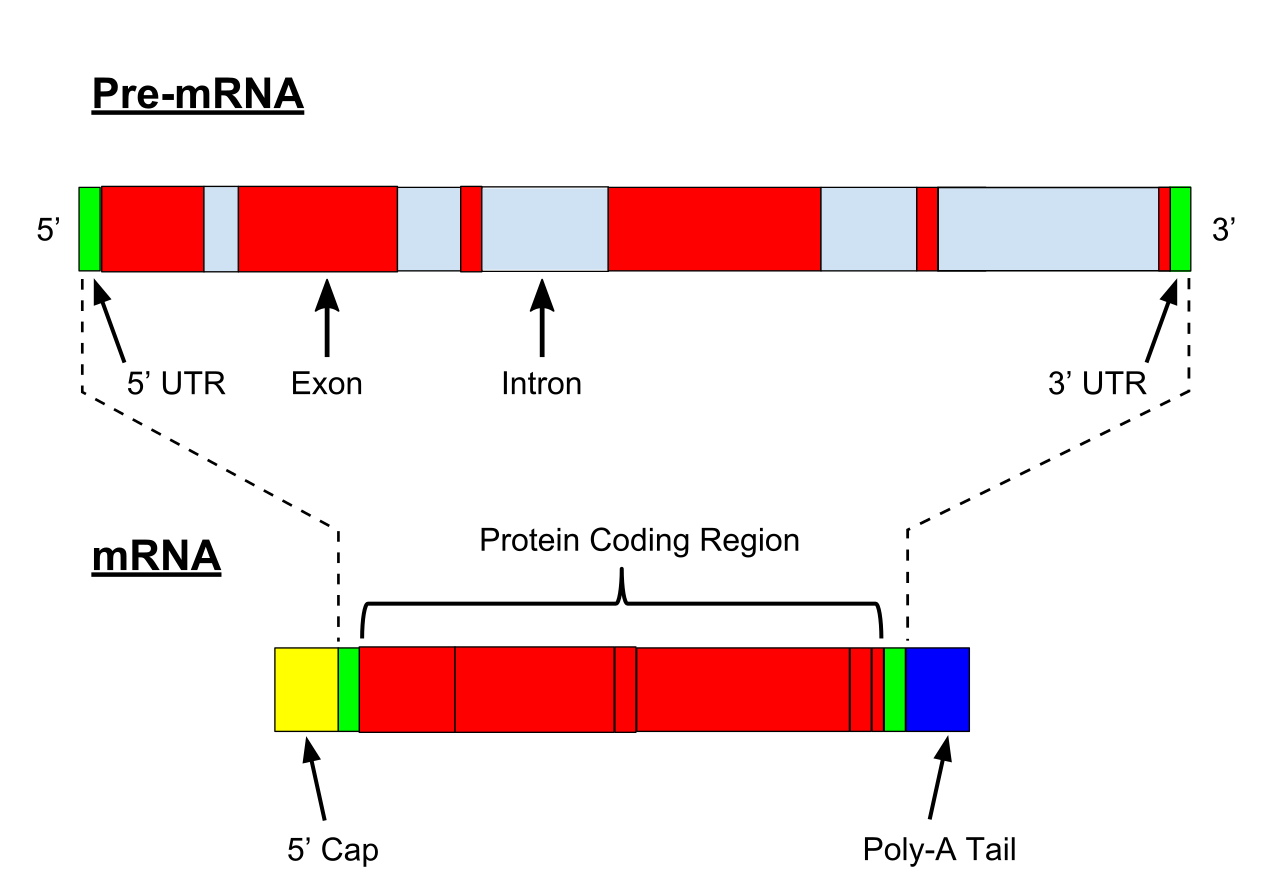
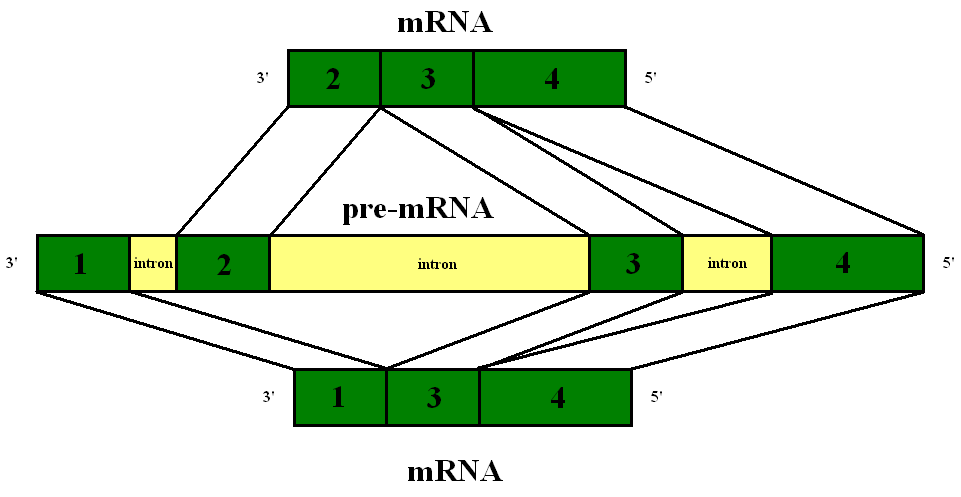
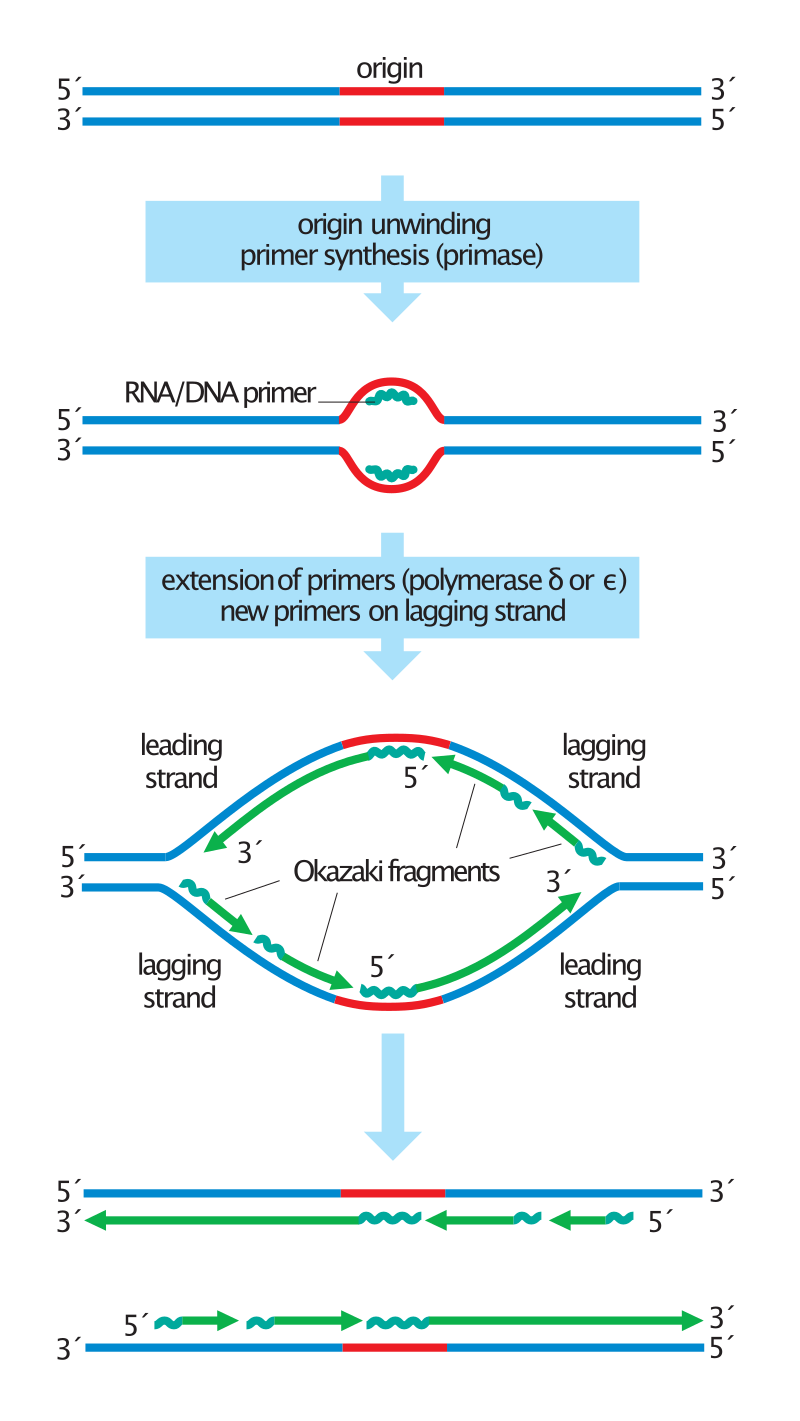
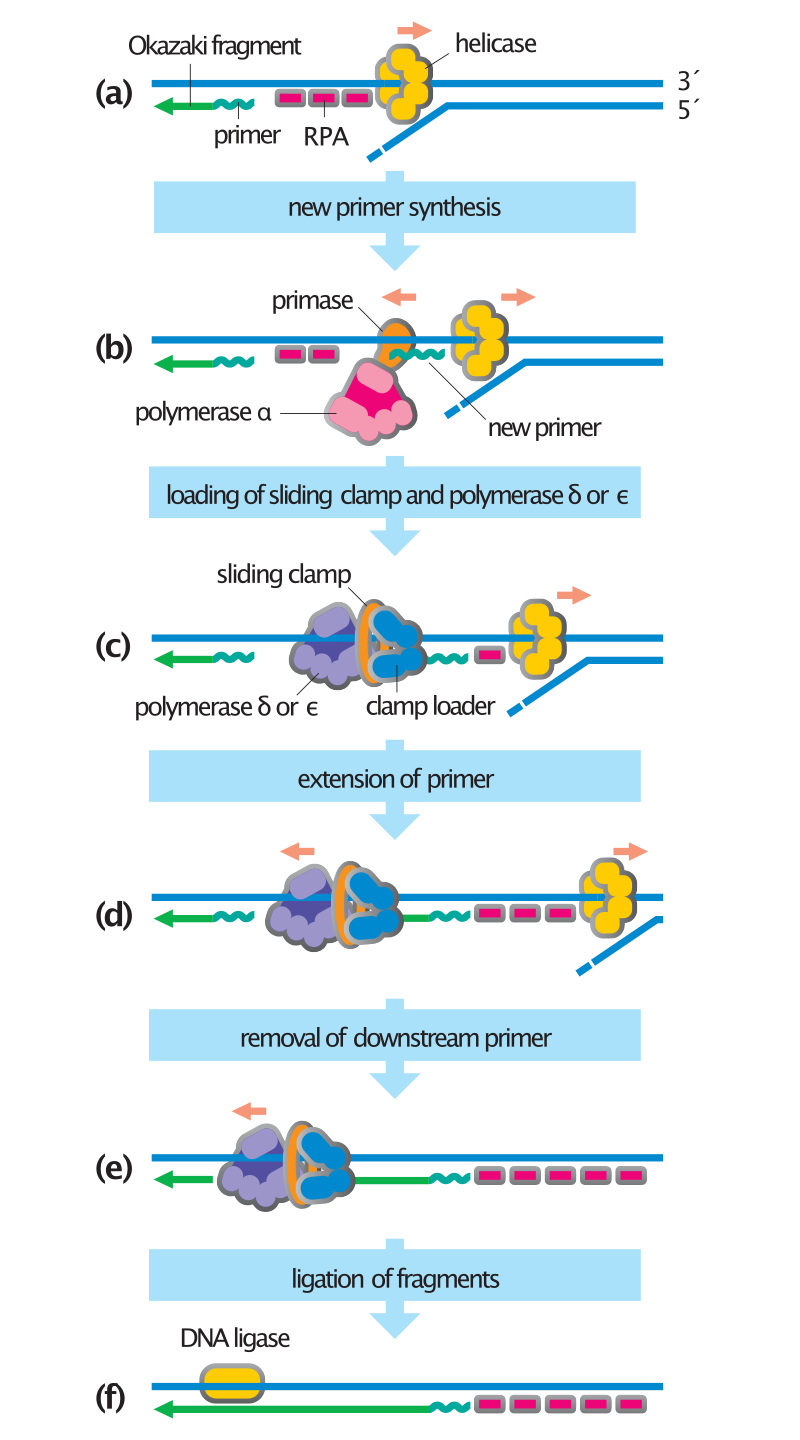
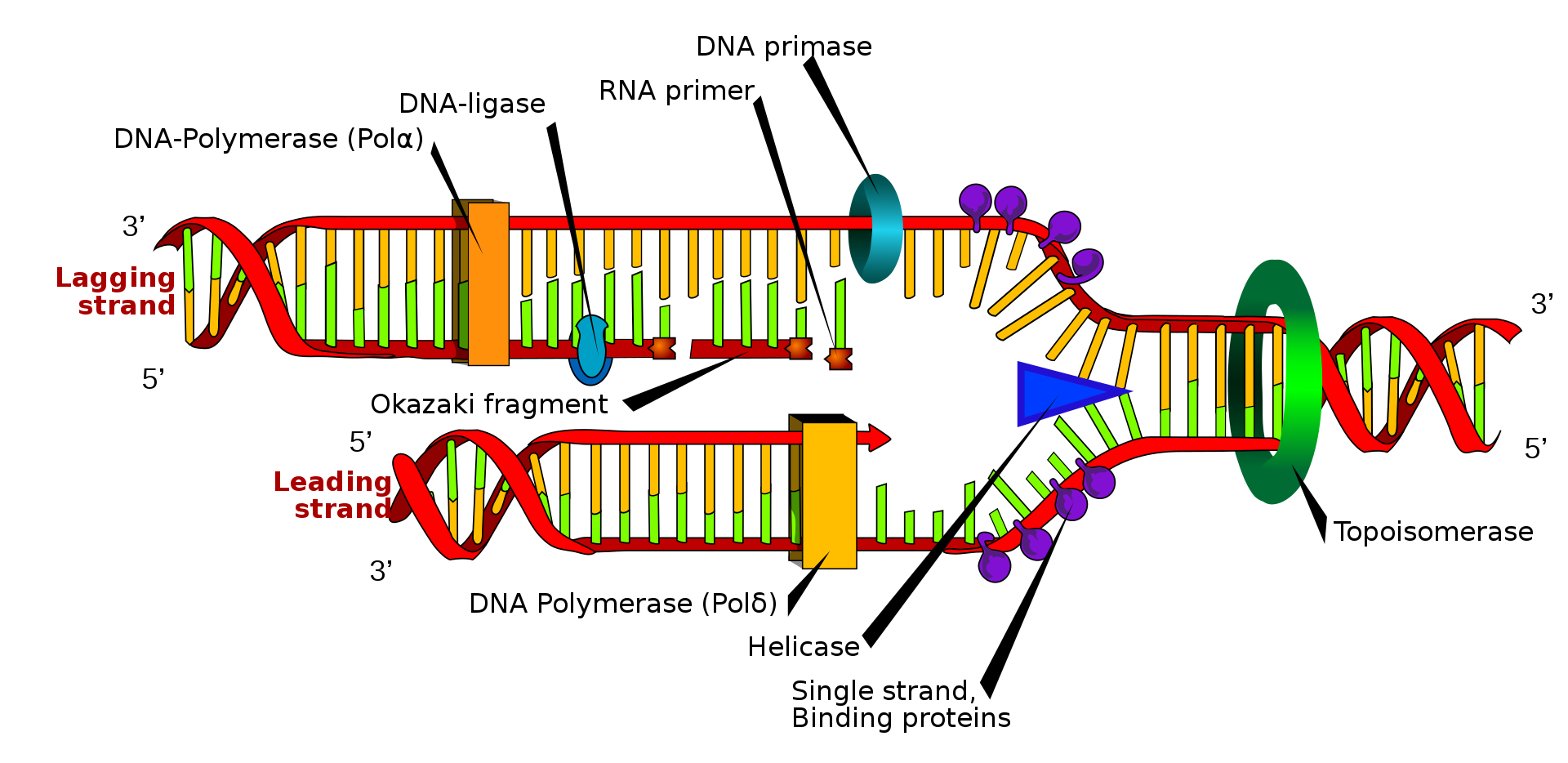
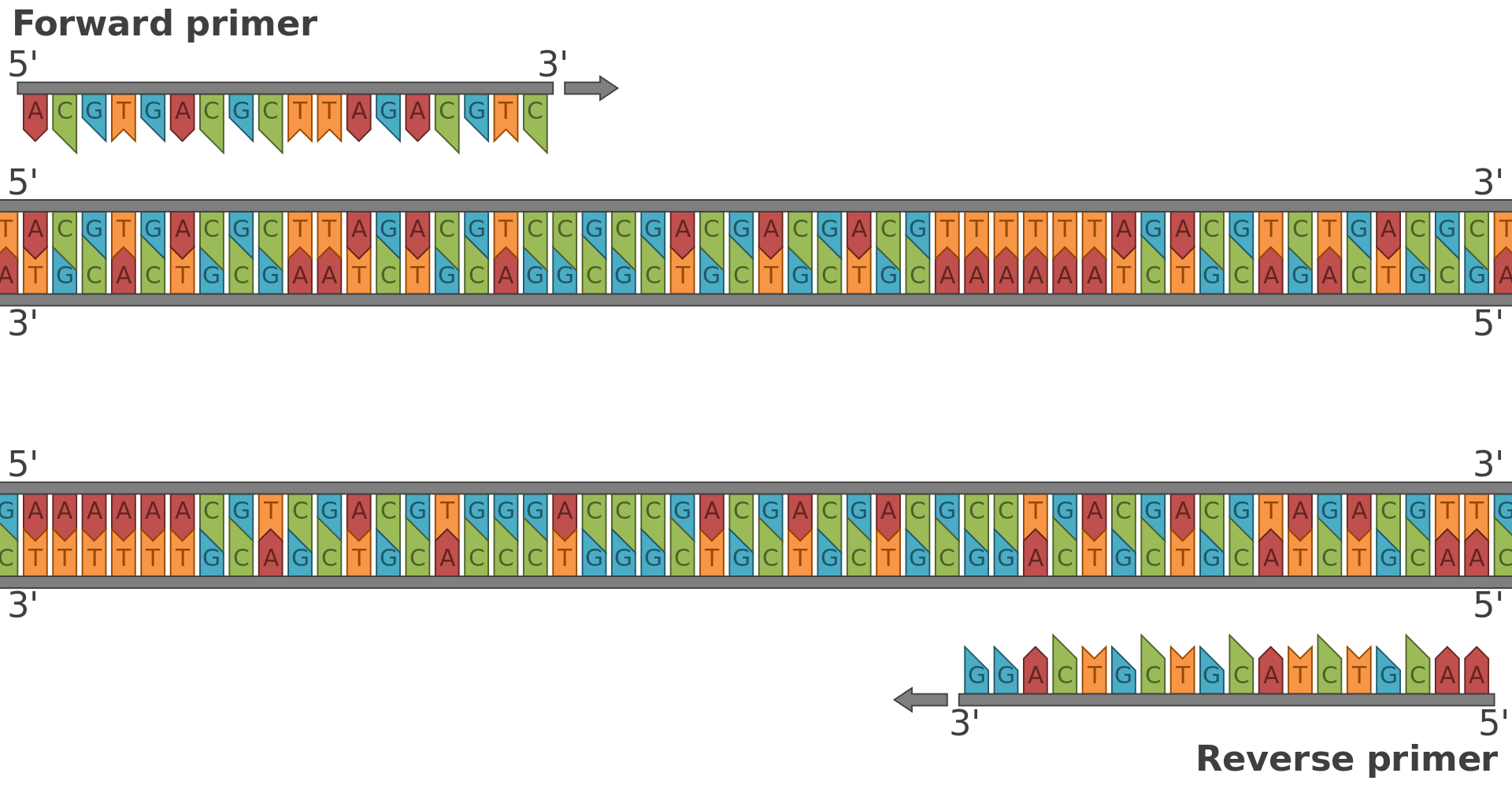
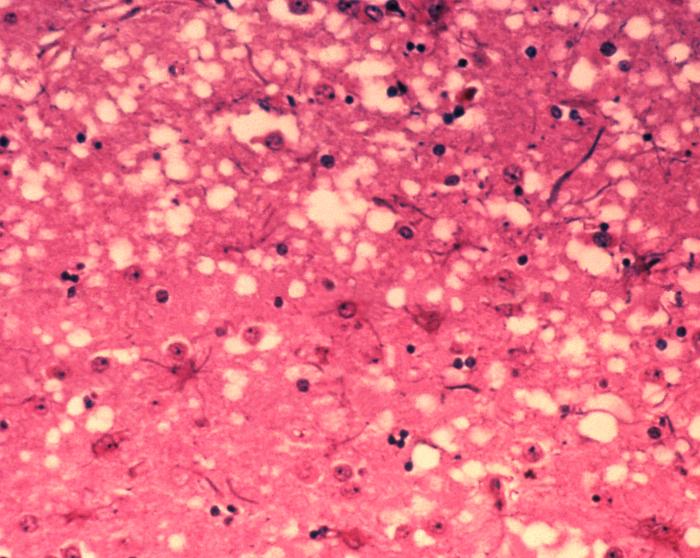
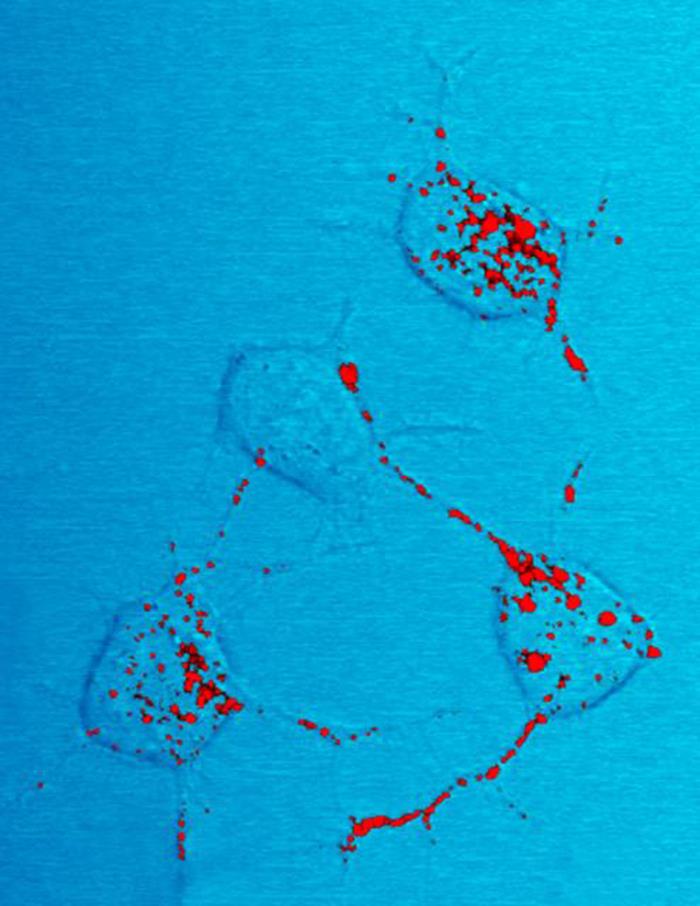
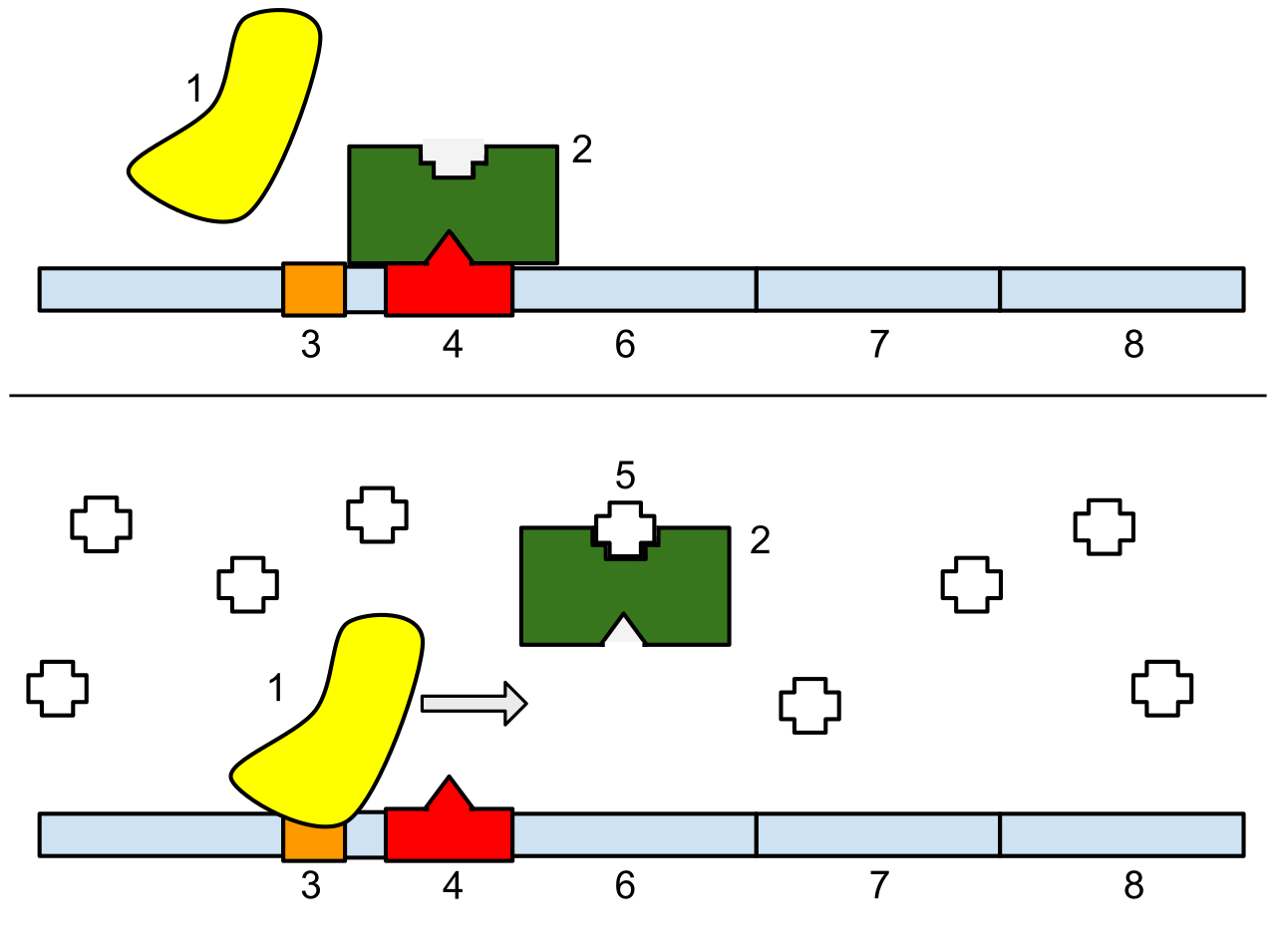
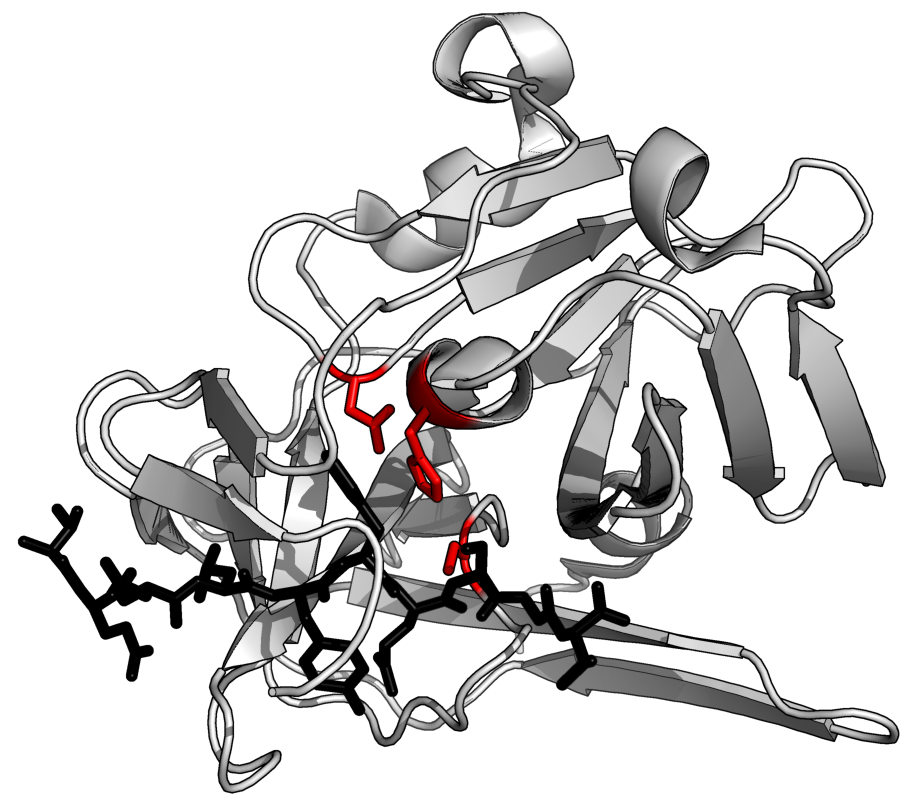

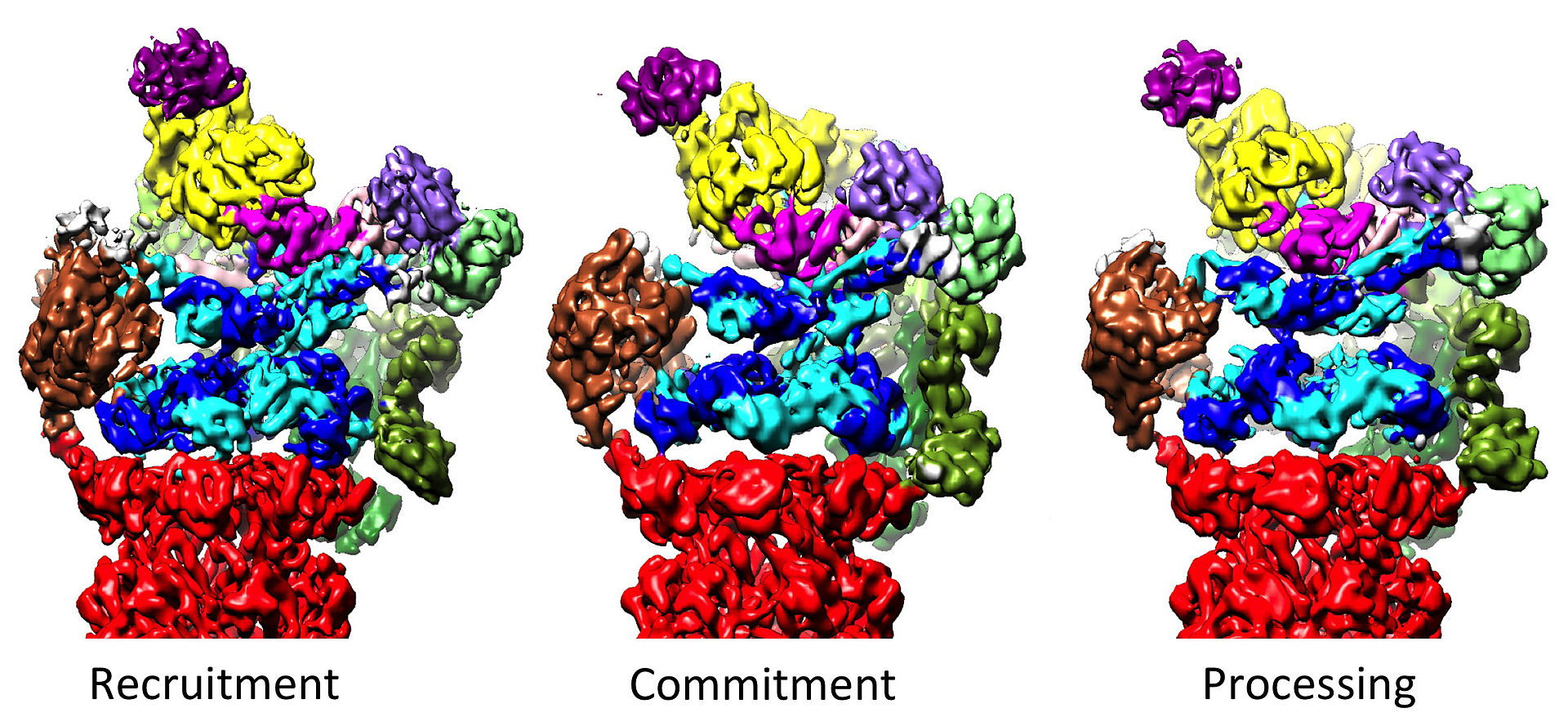
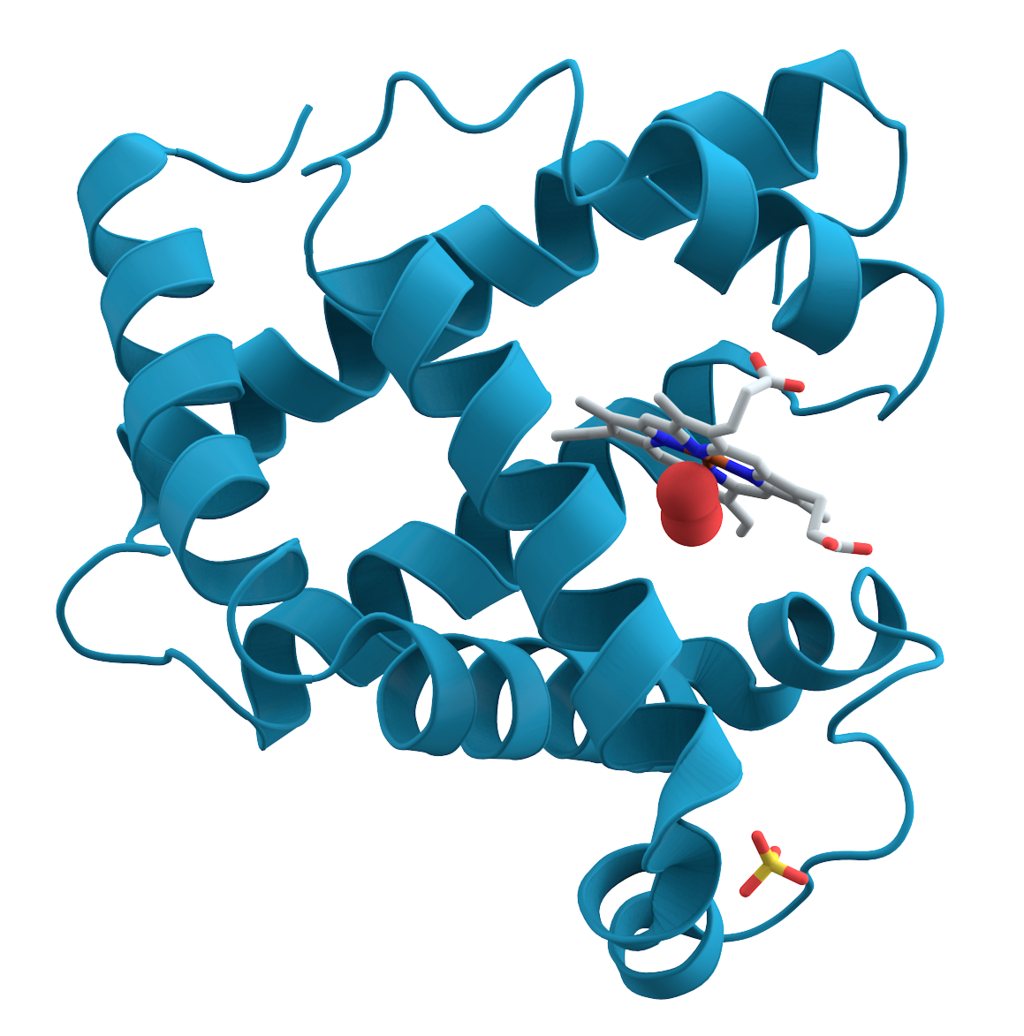
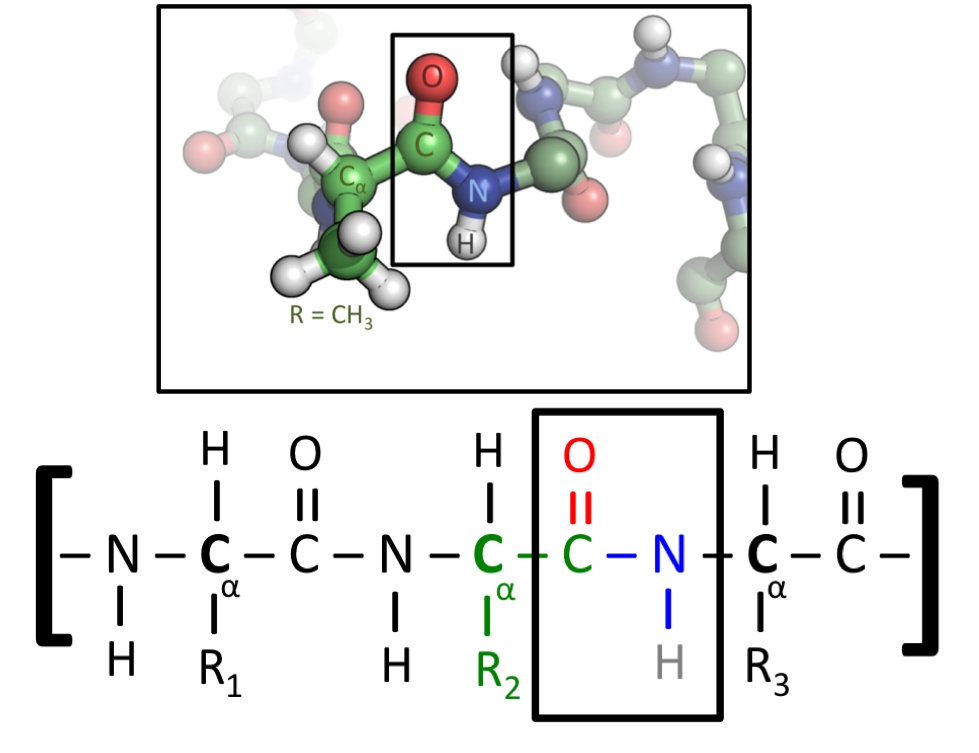

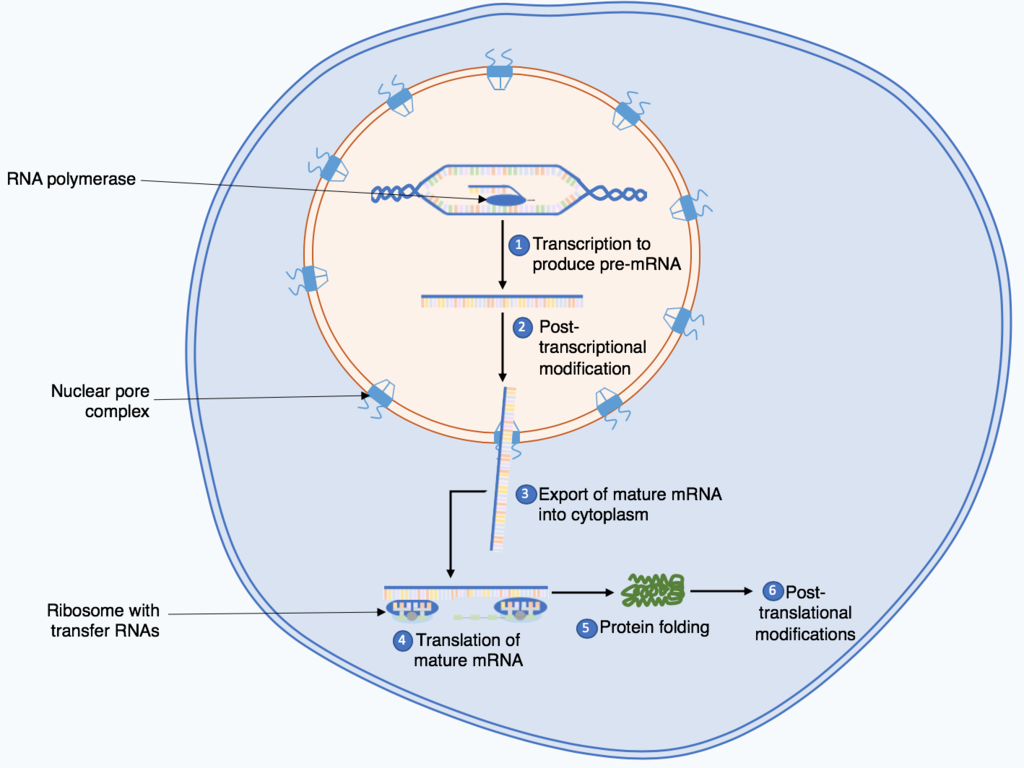
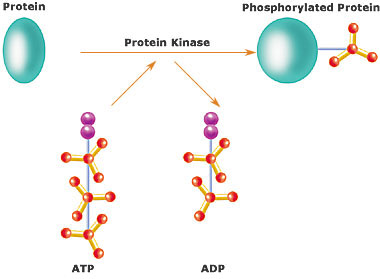
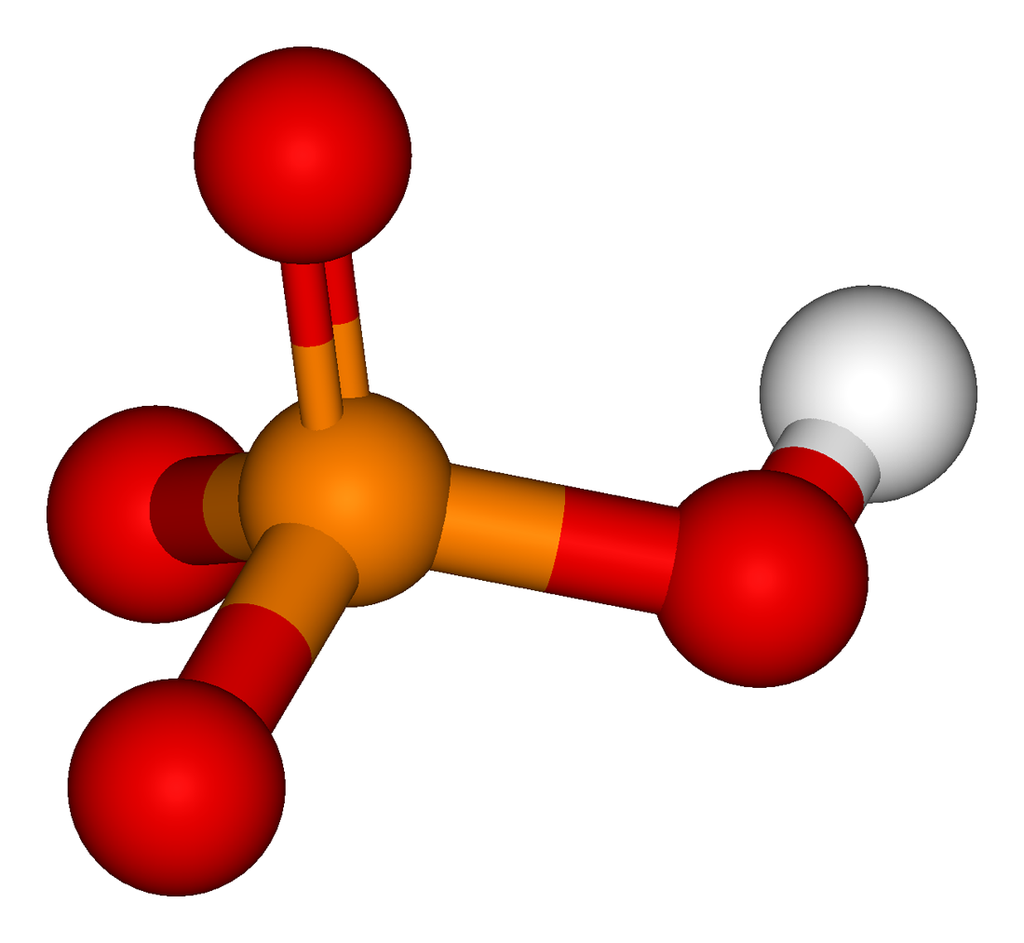
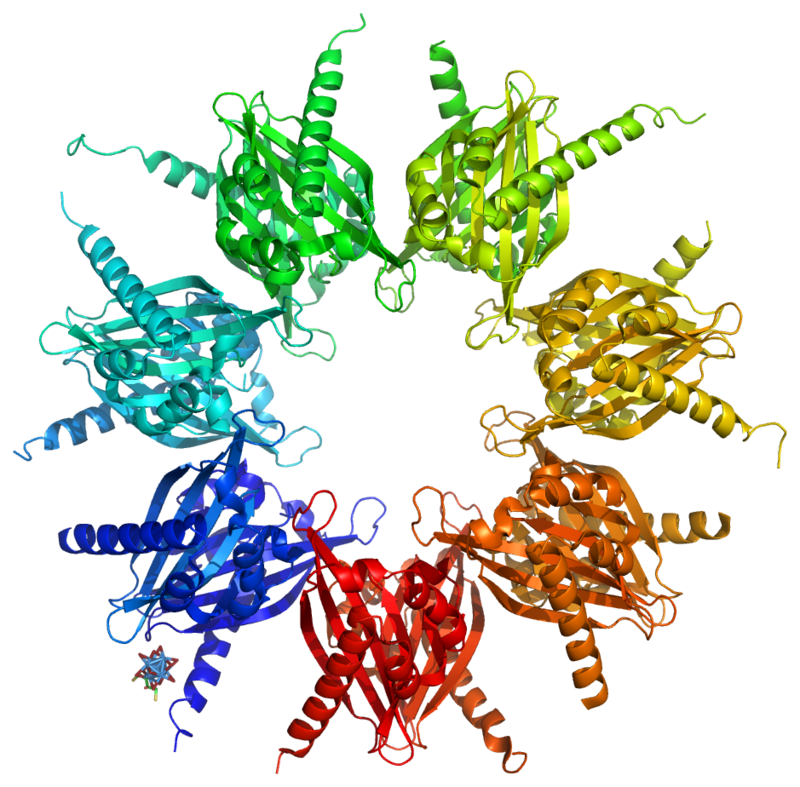
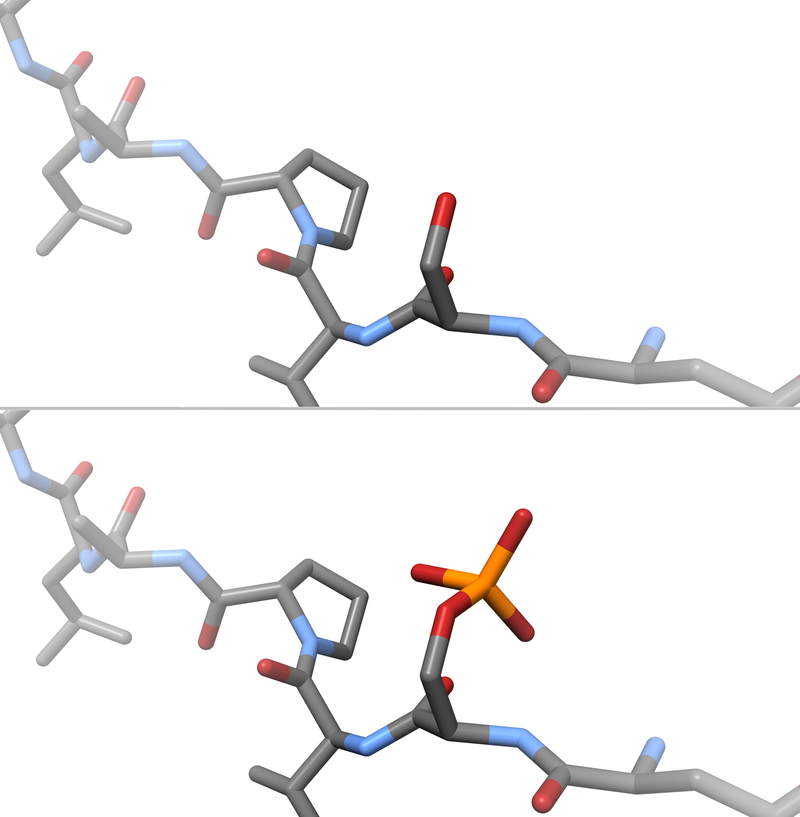
.png)
.png)
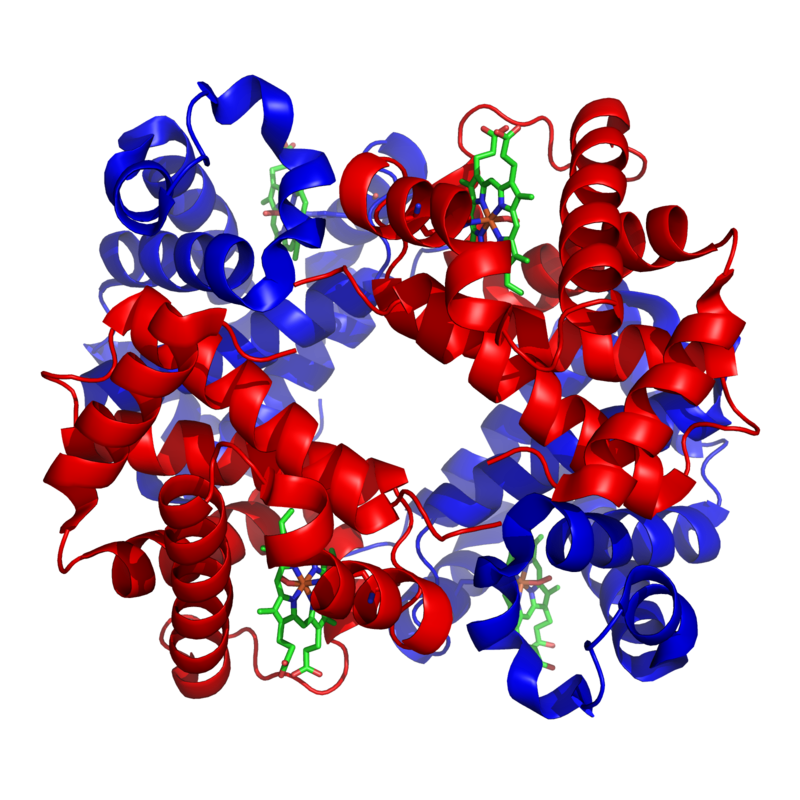
.png)
.png)
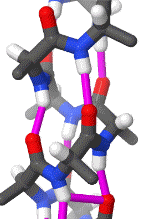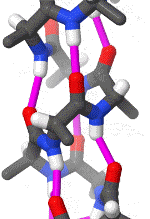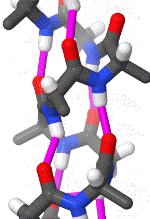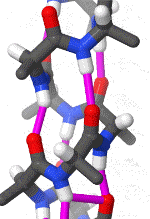
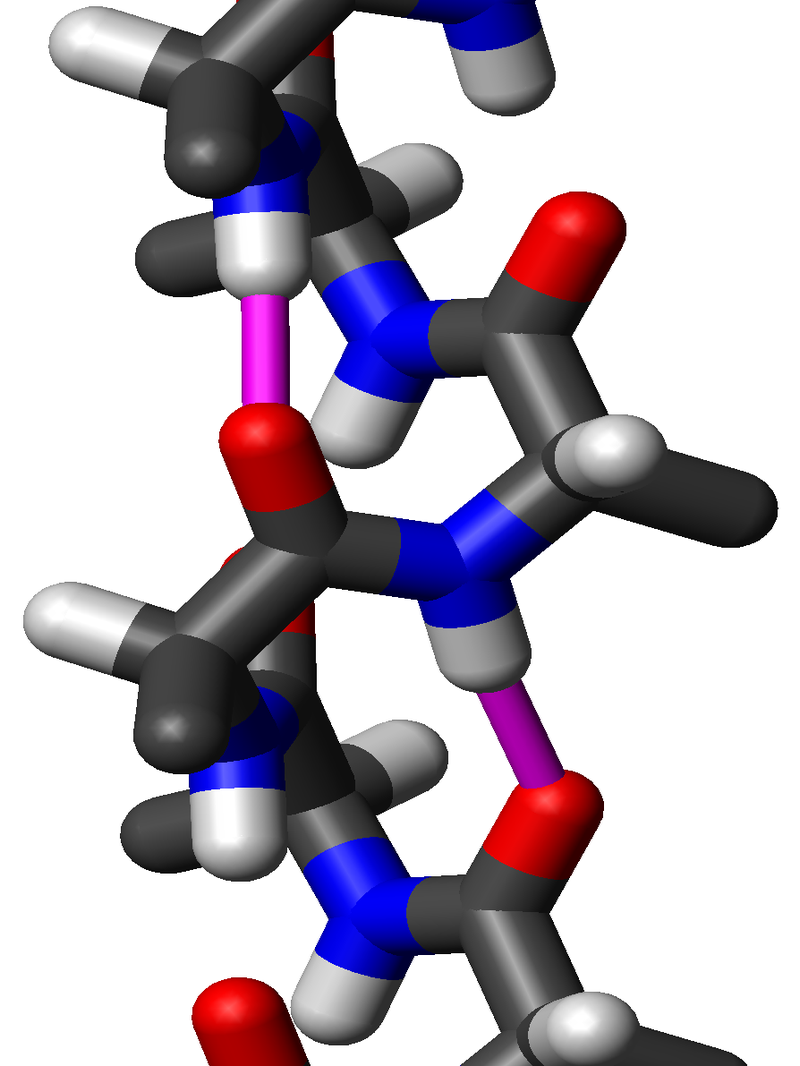
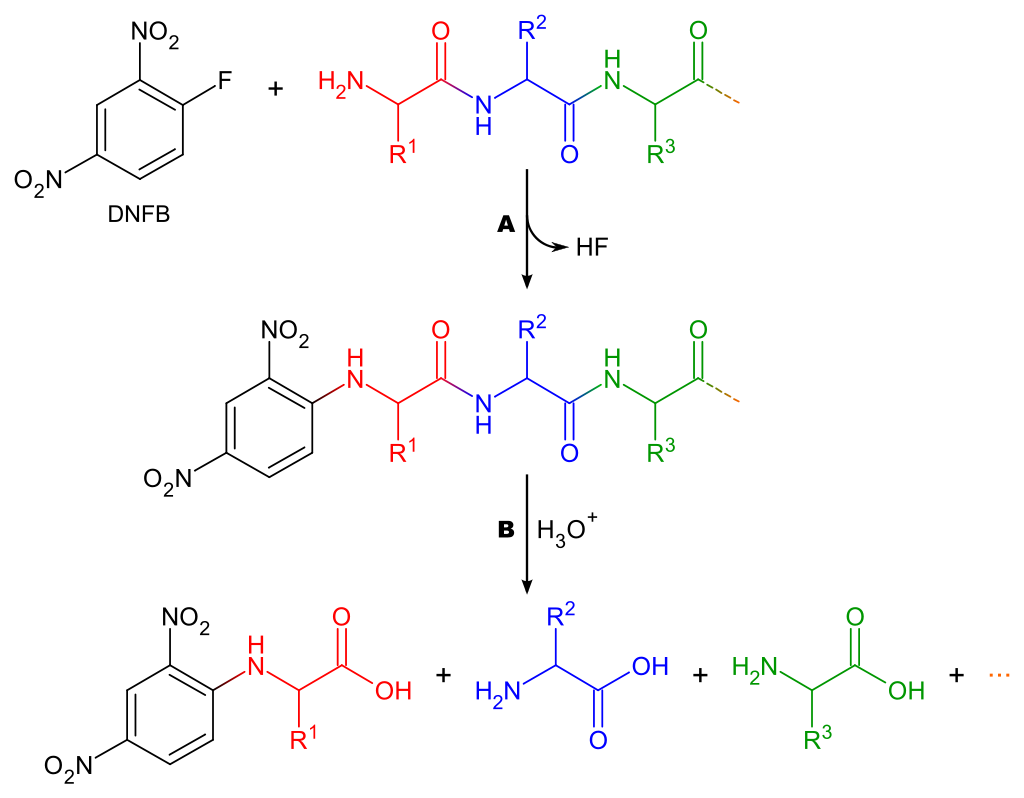
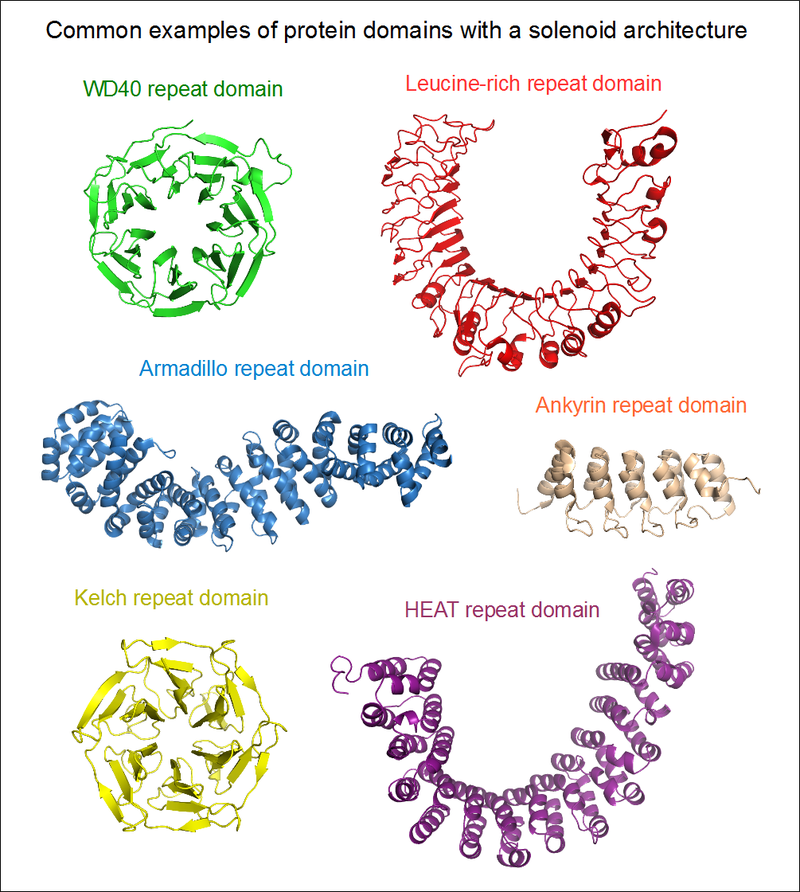

.png)
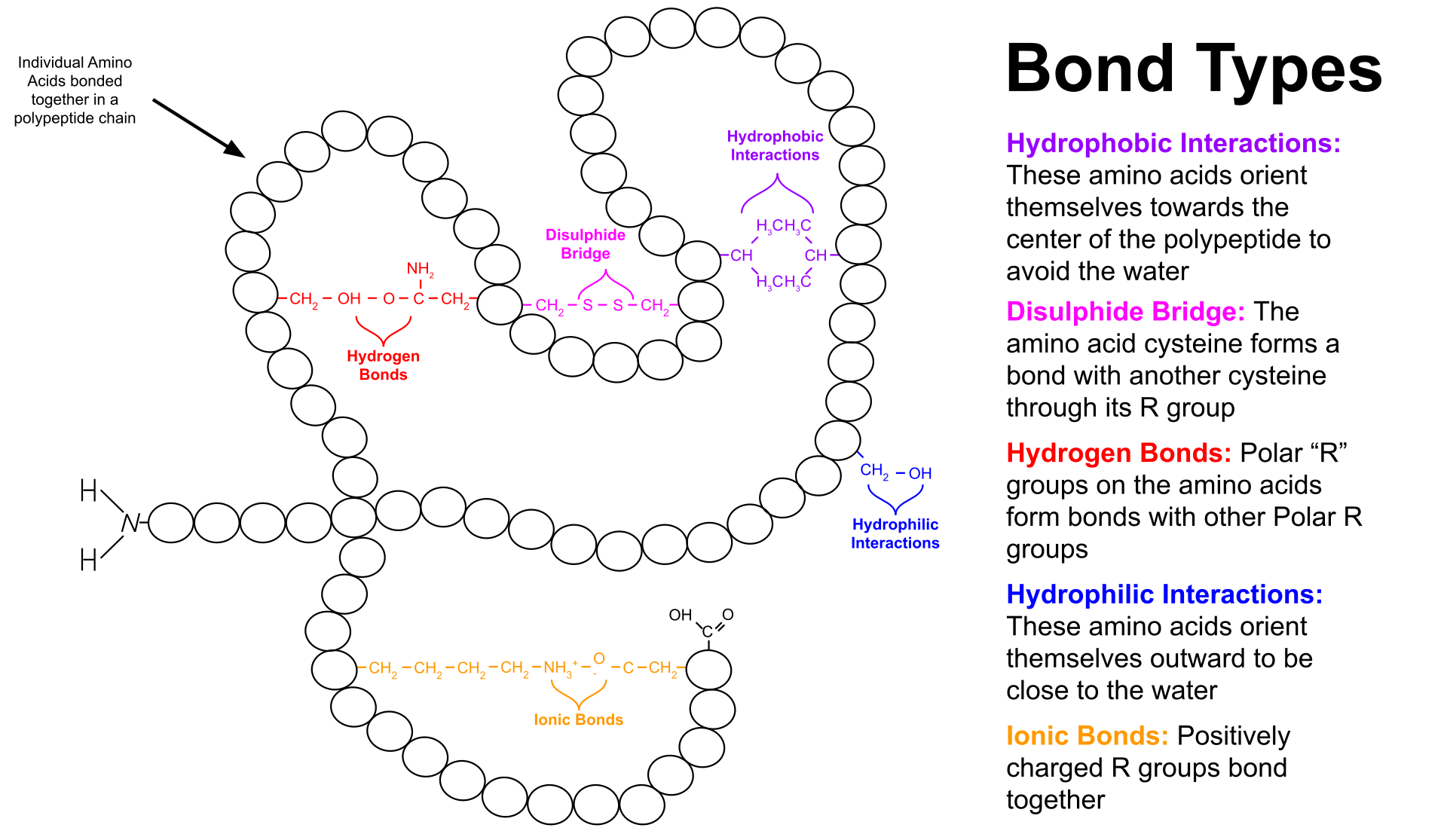
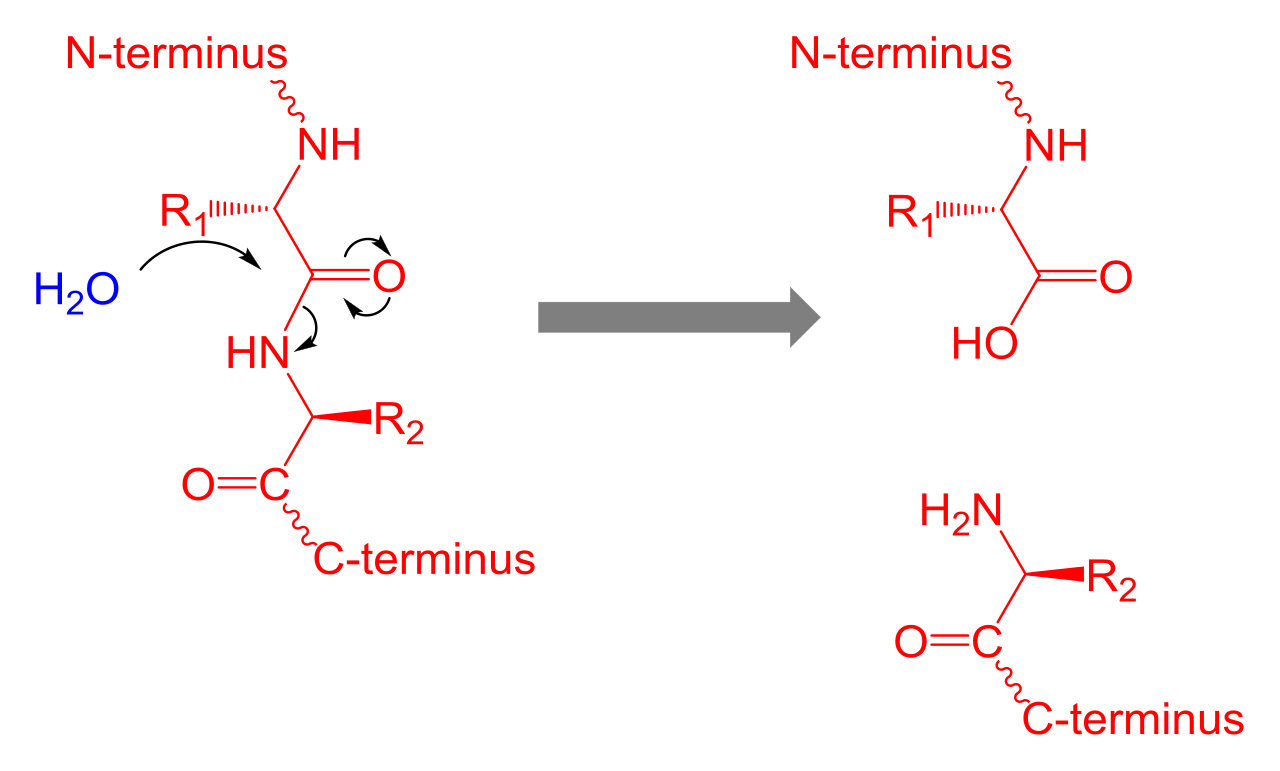
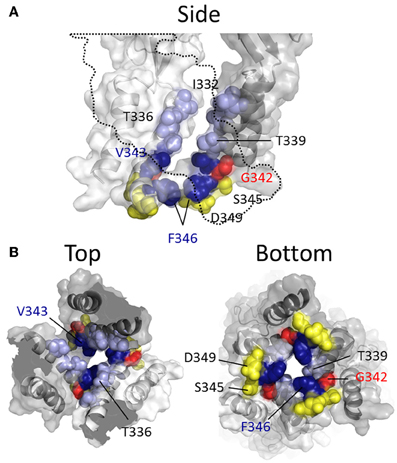

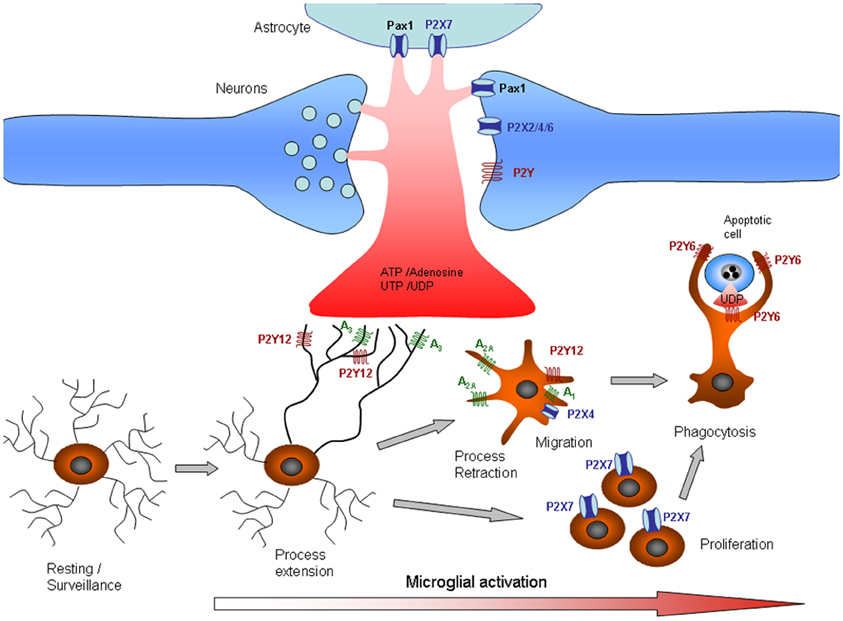
{kind=link}